Developer Guide for Foxit PDF SDK for .NET Core (11.0)
Contents
- Introduction to Foxit PDF SDK
- Getting Started
- Working with SDK API
- Initialize Library
- Document
- Page
- Render
- Attachment
- Text Page
- Text Search
- Search and Replace
- Text Link
- Bookmark
- Form (AcroForm)
- XFA Form
- Form Design
- Annotations
- Image Conversion
- Watermark
- Barcode
- Security
- Reflow
- Asynchronous PDF
- Pressure Sensitive Ink
- Wrapper
- PDF Objects
- Page Object
- Marked content
- Layer
- Signature
- LTV
- PAdES
- PDF Action
- JavaScript
- Redaction
- Comparison
- OCR
- Compliance
- Optimization
- HTML to PDF Conversion
- Office to PDF Conversion with third-party engines
- Office to PDF Conversion with Foxit’s self-developed engines
- Output Preview
- Combination
- PDF Portfolio
- Table Maker
- Accessibility
- PDF to Office Conversion
- DWG to PDF Conversion
- OFD
- Paragraph Editing
- 3D Rendering
- FAQ
- Appendix
- References
- Support
Introduction to Foxit PDF SDK
Have you ever thought about building your own application that can do everything you want with PDF files? If your answer is “Yes”, congratulations! You just found the best solution in the industry that allows you to build stable, secure, efficient and full-featured PDF applications.
Foxit PDF SDK provides high-performance libraries to help any software developer add robust PDF functionality to their enterprise, mobile and cloud applications across all platforms (includes Windows, Mac, Linux, Web, Android, iOS, and UWP), using the most popular development languages and environments.
Why Choose Foxit PDF SDK
Foxit is a leading software provider of solutions for reading, editing, creating, organizing, and securing PDF documents. Foxit PDF SDK libraries have been used in many of today’s leading apps, and are proven, robust, and battle-tested to provide the quality, performance, and features that the industry’s largest apps demand. Customers choose Foxit PDF SDK product for the following reasons:
Easy to integrate
Developers can seamlessly integrate Foxit PDF SDK into their own applications.
Lightweight footprint
Does not exhaust system resource and deploys quickly.
Cross-platform support
Support current mainstream platforms, such as Windows, Mac, Linux, Web, Android, iOS, and UWP.
Powered by Foxit’s high fidelity rendering PDF engine
The core technology of the SDK is based on Foxit’s PDF engine, which is trusted by a large number of the world’s largest and well-known companies. Foxit’s powerful engine makes the app fast on parsing, rendering, and makes document viewing consistent on a variety of devices.
Premium World-side Support
Foxit offers premium support for its developer products because when you are developing mission critical products you need the best support. Foxit has one of the PDF industry’s largest team of support engineers. Updates are released on a regular basis to improve user experience by adding new features and enhancements.
Foxit PDF SDK for .NET Core
Application developers who use Foxit PDF SDK can leverage Foxit’s powerful, standard-compliant PDF technology to securely display, create, edit, annotate, format, organize, print, share, secure, search documents as well as to fill PDF forms. Additionally, Foxit PDF SDK (for C++ and .NET) includes a built-in, embeddable PDF Viewer, making the development process easier and faster. For more detailed information, please visit the website https://developers.foxitsoftware.com/pdf-sdk/.
In this guide, we focus on the introduction of Foxit PDF SDK for .NET Core on Windows, Linux and Mac platforms.
.NET Core is an open-source, general-purpose development platform maintained by Microsoft and the .NET community on GitHub. It’s cross-platform (supporting Windows, Linux, and Mac) and can be used to build device, cloud, and IoT applications.
Foxit PDF SDK for .NET Core ships with simple-to-use APIs that can help .NET Core developers seamlessly integrate powerful PDF technology into their own projects on Windows, Linux and Mac platforms. It provides rich features on PDF documents, such as PDF viewing, bookmark navigating, text selecting/copying/searching, PDF signatures, PDF forms, rights management, PDF annotations, and full text search.
Evaluation
Foxit PDF SDK allows users to download a trial version to evaluate the SDK. The trial version has no difference from a standard version except for the 10-day limitation trial period and the trail watermarks that will be generated on the PDF pages. After the evaluation period expires, customers should contact Foxit sales team and purchase licenses to continue using Foxit PDF SDK.
License
Developers should purchase licenses to use Foxit PDF SDK in their solutions. Licenses grant users permissions to release their applications based on PDF SDK libraries. However, users are prohibited to distribute any documents, sample codes, or source codes in the SDK released package to any third party without the permission from Foxit Software Incorporated.
About this guide
This guide is intended for developers who need to integrate Foxit PDF SDK for .NET Core into their own applications. It aims at introducing the installation package, and the usage of SDK.
Getting Started
It’s very easy to setup Foxit PDF SDK and see it in action! This guide will provide you with a brief introduction on how to integrate Foxit PDF SDK for .NET Core into the projects on Windows, Linux and Mac platforms. The following sections introduce the contents of system requirements, the installation package as well as how to run a demo, and create your own project.
System Requirements
| Platform | System Requirement | Note |
| Windows | Windows 10 and 11 (32-bit, 64-bit) | Visual Studio 2017 version 15.9 or higher |
| Linux | 64-bit OS armv7/armv8 | All Linux for x64 samples have been tested on Ubuntu14.0 64 bit. All Linux for armv7/armv8 samples have been tested on armv7 or armv8 OS. |
| Mac | Mac OS X 10.6 or higher (64-bit) Mac OS 11.2 or higher (arm64) | Visual Studio for Mac 8.0 or higher (64-bit OS) Visual Studio for Mac 2022 or higher (arm64 OS) |
Prerequisites for .NET Core:
Prerequisites for .NET Core 2.1 or higher on Windows, Linux x64/armv7, and macOS x64.
Prerequisites for .NET Core 3.1 or higher on Linux armv8.
Prerequisites for .NET Core 6.0 or higher on macOS arm64.
Windows
What is in the package
Download the Foxit PDF SDK zip for .NET Core (Windows) package and extract it to a new directory. The release package contains the following folders:
doc: API references, developer guide
examples: sample projects and demos
lib: libraries and license files
res: the default icc profile files used for output preview demo
Note: You can obtain this package directly from NuGet.
How to run a demo
Foxit PDF SDK for .NET Core (Windows) provides several simple demos in directory “examples\simple_demo”. All these demos (except security, ocr, compliance, preflight, html2pdf, office2pdf, output preview, pdf2office, dwg2pdf and ofd demos) can be run directly in a command prompt using the “RunDemo.bat” file in directory “examples\simple_demo”.
Open a command prompt, navigate to “examples\simple_demo”, and then run the following command:
For 32-bit operating system, type “RunDemo.bat all x86“ to run all the demos, or type “RunDemo.bat demo_name x86“ to run a specific single demo, for example, “RunDemo.bat bookmark x86“ will only run the bookmark demo.
For 64-bit operating system, type “RunDemo.bat all“ to run all the demos, or type “RunDemo.bat demo_name“ to run a specific single demo, for example, “RunDemo.bat bookmark” will only run the bookmark demo.
“examples\simple_demo\input_files” contains all the input files used among these demos. Some demos will generate output files (pdf, text or image files) to a folder named by the project name under “examples\simple_demo\output_files\” folder.
In “examples\simple_demo\output_files\security” folder, if you want to open the “certificate_encrypt.pdf” document, you should install the certificates “foxit.cer” and “foxit_all.pfx” found in “examples\simple_demo\input_files” folder at first. Please follow the steps below:
To install “foxit.cer”, double-click it to start the certificate import wizard. Then select “Install certificate… > Next > Next > Finish”.
To install “foxit_all.pfx”, double-click it to start the certificate import wizard. Then select “Next > Next > (Type the password “123456” for the private key in the textbox) and click Next > Next > Finish”.
OCR and Compliance/Preflight demos
For ocr and compliance/preflight demos, you should build a resource directory at first, please contact Foxit support team or sales team to get the resource files packages. For more details about how to run the demos, please refer to section “OCR” and section “Compliance”.
HTML to PDF demo
For html2pdf demo, you should contact Foxit support team or sales team to get the engine files package for converting from HTML to PDF at first. For more details about how to run the demo, please refer to section “HTML to PDF Conversion”.
Office to PDF demo
For office2pdf demo, you need to refer to section “Office to PDF Conversion with third-party engines” and “Office to PDF Conversion with Foxit’s self-developed engines”.
Output Preview demo
For output preview demo, you should set the folder path which contains default icc profile files. For more details about how to run the demo, please refer to section “Output Preview”.
PDF to Office demo
For pdf2office demo, you should contact Foxit support team or sales team to get the engine files package for converting from PDF to office at first. For more details about how to run the demo, please refer to section “PDF to Office Conversion”.
DWG to PDF demo
For dwg2pdf demo, you should contact Foxit support team or sales team to get the engine files package for converting from DWG to PDF at first. For more details about how to run the demo, please refer to section “DWG to PDF Conversion”.
OFD demo
For ofd demo, you should contact Foxit support team or sales team to get the OFD engine files package at first. For more details about how to run the demo, please refer to section “OFD”.
How to create a simple project
In this section, we will show you how to use Foxit PDF SDK for .NET Core to create a simple project that renders the first page of a PDF to a bitmap and saves it as a JPG image. The project will take .NET Core 2.1 and 64-bit operating system for example. To create the project, please follow the steps below:
Open Visual Studio 2017 and create a new .NET Core Console App (with C#) named “test_dotnetcore”.
Copy the “lib” folder from the “foxitpdfsdk_11_0_win_dotnetcore” folder to the project “test_dotnetcore” folder.
Add Foxit PDF SDK for .NET Core dynamic library to Dependencies. In order to use Foxit PDF SDK APIs in the project, you must first add a reference to it.
In Solution Explorer, right-click the Dependencies node of your project and click Add Reference…
In the Reference Manager dialog, click Browse tab, navigate to the “test_dotnetcore\lib\x64_vc17”, “test_dotnetcore\lib\x86_vc17” or “test_dotnetcore\lib\anycpu_vc17” folder depending on your operating system. Here, we use 64-bit operating system, so navigate to the “test_dotnetcore\lib\x64_vc17” folder, select fsdk_dotnetcore.dll dynamic library, and then click OK.
Add “fsdk.dll” to the project.
For the Win32 or Win64 platform target, right-click the “test_dotnetcore” project and click Add > Existing Item…, navigate to the “test_dotnetcore\lib\x64_vc17” or “test_dotnetcore\lib\x86_vc17”, select fsdk.dll dynamic library, and click Add.
For the AnyCPU platform target:
Right-click the “test_dotnetcore” project and click Add > New Folder… to add a folder named “x64”. Then right-click the “x64” folder and click Add > Existing Item…, navigate to the ” test_dotnetcore\lib\x64_vc17\”, select fsdk.dll dynamic library, and click Add.
Right-click the “test_dotnetcore” project and click Add > New Folder… to add a folder named “x86”. Then right-click the “x86” folder and click Add > Existing Item…, navigate to the “test_dotnetcore\lib\x86_vc17\”, select fsdk.dll dynamic library, and click Add.
Note:
Please make sure to set the property “Copy to Output Directory” of “fsdk.dll” to “Copy if newer”. Otherwise, you should copy it to the same folder with the executable file manually before running the project.
For AnyCPU, it is necessary to successfully call Library.Initialize before creating the SDK object.
Change the build architecture of the project.
Click on Build -> Configuration Manager… and select x64 for “Active solution platform”.
Note: You should choose the proper platform for the build architecture according to your operating system.
Copy a PDF file (“Sample.pdf” for example) to the “test_dotnetcore\test_dotnetcore” folder, which will be used to test the project.
Note: Please make sure to set the property “Copy to Output Directory” of the “Sample.pdf” to “Copy if newer”. Otherwise, you should copy it to the same folder with the executable file manually before running the project.
Then, the test_dotnetcore project will look like the Figure 2-1.
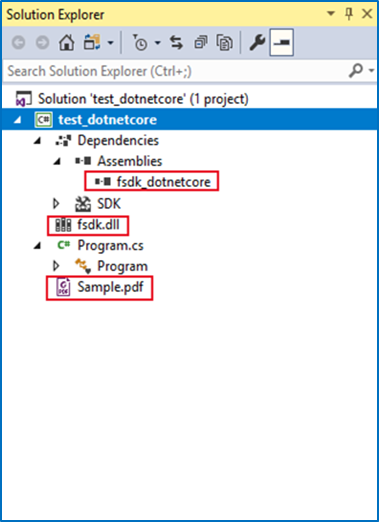
Figure 2-1
Note: After finishing the step 3 to step 7, right-click the “test_dotnetcore” project and click Edit test_dotnetcore.csproj, then you can see the contents of test_dotnetcore.csproj file are as follows:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp2.1</TargetFramework>
<Platforms>AnyCPU;x64</Platforms>
</PropertyGroup>
<ItemGroup>
<Reference Include="fsdk_dotnetcore">
<HintPath>..\lib\x64_vc17\fsdk_dotnetcore.dll</HintPath>
</Reference>
</ItemGroup>
<ItemGroup>
<None Update="fsdk.dll">
<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>
</None>
<None Update="Sample.pdf">
<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>
</None>
</ItemGroup>
</Project>
When creating your own project, you can manually edit the “.csproj” file directly instead of doing the operations from step 3 to step 7, and only need to configure the paths of the fsdk_dotnetcore.dll and fsdk.dll according to your project.
Add using statement to the beginning of the “Program.cs“.
using foxit.common; using foxit.common.fxcrt; using foxit.pdf;
Initialize Foxit PDF SDK library. It is necessary for apps to initialize Foxit PDF SDK using a license before calling any APIs. The trial license files can be found in the “lib” folder.
string sn = " ";
string key = " ";
ErrorCode error_code = Library.Initialize(sn, key);
if (error_code != ErrorCode.e_ErrSuccess)
{
return;
}
Note The value of “sn“ can be got from “gsdk_sn.txt“ (the string after “SN=“) and the value of “key“ can be got from “gsdk_key.txt“ (the string after “Sign=“).
Load a PDF (Sample.pdf) document, and parse the first page of the document.
PDFDoc doc = new PDFDoc("Sample.pdf");
error_code = doc.LoadW("");
if (error_code != ErrorCode.e_ErrSuccess)
{
return;
}
// Get the first page of the document.
PDFPage page = doc.GetPage(0);
// Parse page.
page.StartParse((int)foxit.pdf.PDFPage.ParseFlags.e_ParsePageNormal, null, false);
Render a Page to a bitmap and save it as a JPG file.
int width = (int)(page.GetWidth());
int height = (int)(page.GetHeight());
Matrix2D matrix = page.GetDisplayMatrix(0, 0, width, height, page.GetRotation());
// Prepare a bitmap for rendering.
foixt.common.Bitmap bitmap = new foxit.common.Bitmap(width, height, foxit.common.Bitmap.DIBFormat.e_DIBRgb32);
bitmap.FillRect(0xFFFFFFFF, null);
// Render page
Renderer render = new Renderer(bitmap, false);
render.StartRender(page, matrix, null);
// Add the bitmap to image and save the image.
foxit.common.Image image = new foxit.common.Image();
image.AddFrame(bitmap);
image.SaveAs("testpage.jpg");
Click “Build > Build Solution” to build the project.
Click “Debug > Start Without Debugging” to run the project, and then the “testpage.jpg” will be generated in the output directory (“test_dotnetcore\test_dotnetcore\bin\x64\Debug\netcoreapp2.1”).
Note:
For the Win32 or Win64 platform target, please check whether the “fsdk.dll” and “fsdk_dotnetcore.dll” have been copied to the output directory.
For the AnyCPU platform target, please check whether the “fsdk_dotnetcore.dll” has been copied to the output directory. Additionally, ensure that the “fsdk.dll” from the “x64_vc17” folder has been correctly placed in the “x64” folder, and the “fsdk.dll” from the “x86_vc17” folder is appropriately located in the “x86” folder along with the output directory. If not, you should put the dynamic libraries to the folder manually.
The final contents of “Program.cs“ are as follows:
using System;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
namespace test_dotnetcore
{
class Program
{
static void Main(string[] args)
{
// The value of "sn" can be got from "gsdk_sn.txt" (the string after "SN=").
// The value of "key" can be got from "gsdk_key.txt" (the string after "Sign=").
string sn = " ";
string key = " ";
ErrorCode error_code = Library.Initialize(sn, key);
if (error_code != ErrorCode.e_ErrSuccess)
{
return;
}
using (PDFDoc doc = new PDFDoc("Sample.pdf"))
{
error_code = doc.LoadW("");
if (error_code != ErrorCode.e_ErrSuccess)
{
Library.Release();
return;
}
using (PDFPage page = doc.GetPage(0))
{
// Parse page.
page.StartParse((int)foxit.pdf.PDFPage.ParseFlags.e_ParsePageNormal, null, false);
int width = (int)(page.GetWidth());
int height = (int)(page.GetHeight());
Matrix2D matrix = page.GetDisplayMatrix(0, 0, width, height, page.GetRotation());
// Prepare a bitmap for rendering.
foxit.common.Bitmap bitmap = new foxit.common.Bitmap(width, height, foxit.common.Bitmap.DIBFormat.e_DIBArgb, System.IntPtr.Zero, 0);
bitmap.FillRect(0xFFFFFFFF, null);
// Render page
Renderer render = new Renderer(bitmap, false);
render.StartRender(page, matrix, null);
// Add the bitmap to image and save the image.
foxit.common.Image image = new foxit.common.Image();
image.AddFrame(bitmap);
image.SaveAs("testpage.jpg");
}
}
Library.Release();
}
}
}
Linux
What is in the package
Download the Foxit PDF SDK zip for .NET Core (Linux for x64 or armv7/armv8) package and extract it to a new directory. The release package contains the following folders:
doc: API references, developer guide
examples: sample projects and demos
lib: libraries and license files
res: the default icc profile files used for output preview demo
Note:
You can obtain this package directly from NuGet.
Linux armv7/armv8 does not support the PDF preview feature, so the arm library does not include the ‘res’ directory.
How to run a demo
GCC compiler update on Linux
Starting from version 11.0 of Foxit PDF SDK for Linux (x64), the minimum supported version of GCC compiler has been upgraded from gcc4.9.4 to gcc5.4. For the SDK to work properly, make sure your current GCC version is 5.4 or higher, or the libstdc++.so.6 is 6.0.20 or higher.
The following is the list for minimum version support for current release of Foxit PDF SDK:
| OS | Tool chain | GLIBC |
| Linux x64 | gcc5.4 | GLIBC_2.17 |
| Linux armv7 | gcc-arm-8.3-2019.03-x86_64-arm-linux-gnueabihf | GLIBC_2.28 |
| Linux armv8 | gcc-arm-8.3-2019.03-x86_64-aarch64-linux-gnu | GLIBC_2.27 |
Simple Demo
Before running the demos, please make sure you have configured the .NET Core environment on 64-bit Linux correctly.
Foxit PDF SDK for .NET Core (Linux for x64 or armv7/armv8) provides several simple demos in directory “examples/simple_demo”. All these demos (except ocr, compliance, preflight, html2pdf, office2pdf, output preview, pdf2office, dwg2pdf and ofd demos) can be run directly in a terminal using the “RunDemo.sh” file in directory “examples/simple_demo”.
Open a terminal, navigate to “examples/simple_demo”, and then run the following command:
Type “./RunDemo.sh all“ to run all the demos.
Type “./RunDemo.sh demo_name“ to run a specific single demo, for example, “./RunDemo.sh bookmark” will only run the bookmark demo.
“examples/simple_demo/input_files” contains all the input files used among these demos. Some demos will generate output files (pdf, text or image files) to a folder named by the project name under “examples/simple_demo/output_files/” folder.
OCR and Compliance/Preflight demos (for Linux x64)
For how to run the ocr and compliance/preflight demos, please refer to section “OCR” and section “Compliance”.
HTML to PDF demo (for Linux x64)
For how to run the html2pdf demo, please refer to section “HTML to PDF Conversion”.
Office to PDF demo (for Linux x64 and armv8)
For office2pdf demo, you need to refer to section “Office to PDF Conversion with third-party engines” and “Office to PDF Conversion with Foxit’s self-developed engines”.
Output Preview demo (for Linux x64)
For how to run the output preview demo, please refer to section “Output Preview”.
PDF to Office demo
For how to run the pdf2office demo, please refer to section “PDF to Office Conversion”.
DWG to PDF demo (for Linux x64)
For how to run the dwg2pdf demo, please refer to section “DWG to PDF Conversion”.
OFD demo (for Linux x64 and armv8)
For how to run the ofd demo, please refer to section “OFD”.
How to create a simple project
In this section, we will show you how to use Foxit PDF SDK for .NET Core to create a simple project that renders the first page of a PDF to a bitmap and saves it as a JPG image. The project will take .NET Core 6.0 for example. To create the project, please follow the steps below:
Create a new .NET Core Console App (with C#) named “test_dotnetcore”. Open a terminal, navigate to the directory where you wish to create your project, and run the following command:
dotnet new console -lang C# -o test_dotnetcore
Then, the test_dotnetcore project will be shown as the Figure 2-9.
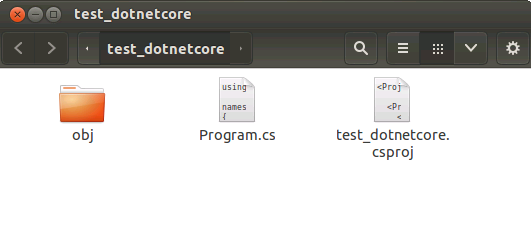
Figure 2-9
For Linux x64, copy the “lib” folder from the “foxitpdfsdk_11_0_linux64_dotnetcore” folder to the project “test_dotnetcore” folder.
For Linux armv7/armv8, copy the “lib” folder from the “foxitpdfsdk_11_0_linuxarm_dotnetcore” folder to the project “test_dotnetcore” folder.
Copy a PDF file (“Sample.pdf” for example) to the “test_dotnetcore” folder, which will be used to test the project.
Add references to the “fsdk_dotnetcore.dll”, as well as add “libfsdk.so”.
Edit the test_dotnetcore.csproj file and add the following code: (For better viewing, I paste the code to Visual Studio to highlight the code)
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net6.0</TargetFramework>
</PropertyGroup>
<ItemGroup >
<FSdkLibSourceFiles Include="lib/libfsdk.so" />
<FSdkArmv7LibSourceFiles Include="lib/armv7/libfsdk.so" />
<FSdkArmv8LibSourceFiles Include="lib/armv8/libfsdk.so" />
</ItemGroup>
<Target Name="DetectArch" BeforeTargets="ResolveAssemblyReferences">
<Exec Command="uname -m" ConsoleToMSBuild="true">
<Output TaskParameter="ConsoleOutput" PropertyName="SystemArch" />
</Exec>
<Message Text="Detected architecture: $(SystemArch)" Importance="high" />
<ItemGroup Condition="'$(SystemArch)' == 'x86_64'">
<Reference Include="fsdk_dotnetcore">
<HintPath>lib/fsdk_dotnetcore.dll</HintPath>
</Reference>
</ItemGroup>
<ItemGroup Condition="'$(SystemArch)' == 'armv7l'">
<Reference Include="fsdk_dotnetcore">
<HintPath>lib/armv7/fsdk_dotnetcore.dll</HintPath>
</Reference>
</ItemGroup>
<ItemGroup Condition="'$(SystemArch)' == 'aarch64'">
<Reference Include="fsdk_dotnetcore">
<HintPath>lib/armv8/fsdk_dotnetcore.dll</HintPath>
</Reference>
</ItemGroup>
<ItemGroup Condition="'$(SystemArch)' == 'x86_64'">
<Message Text="Detected architecture: $(SystemArch)" Importance="high" />
<ReferenceCopyLocalPaths Include="@(FSdkLibSourceFiles)"/>
</ItemGroup>
<ItemGroup Condition="'$(SystemArch)' == 'armv7l'">
<ReferenceCopyLocalPaths Include="@(FSdkArmv7LibSourceFiles)"/>
</ItemGroup>
<ItemGroup Condition="'$(SystemArch)' == 'aarch64'">
<ReferenceCopyLocalPaths Include="@(FSdkArmv8LibSourceFiles)" />
</ItemGroup>
</Target>
<ItemGroup>
<None Update="Sample.pdf">
<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>
</None>
</ItemGroup>
</Project>
Open Program.cs in any text editor and add the below code: (For better viewing, I paste the code to Visual Studio to highlight the code)
using System;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
namespace test_dotnetcore
{
class Program
{
static void Main(string[] args)
{
// The value of "sn" can be got from "gsdk_sn.txt" (the string after "SN=").
// The value of "key" can be got from "gsdk_key.txt" (the string after "Sign=").
string sn = " ";
string key = " ";
ErrorCode error_code = Library.Initialize(sn, key);
if (error_code != ErrorCode.e_ErrSuccess)
{
return;
}
using (PDFDoc doc = new PDFDoc("Sample.pdf"))
{
error_code = doc.LoadW("");
if (error_code != ErrorCode.e_ErrSuccess)
{
Library.Release();
return;
}
using (PDFPage page = doc.GetPage(0))
{
// Parse page.
page.StartParse((int)foxit.pdf.PDFPage.ParseFlags.e_ParsePageNormal, null, false);
int width = (int)(page.GetWidth());
int height = (int)(page.GetHeight());
Matrix2D matrix = page.GetDisplayMatrix(0, 0, width, height, page.GetRotation());
// Prepare a bitmap for rendering.
foxit.common.Bitmap bitmap = new foxit.common.Bitmap(width, height, foxit.common.Bitmap.DIBFormat.e_DIBArgb, System.IntPtr.Zero, 0);
bitmap.FillRect(0xFFFFFFFF, null);
// Render page
Renderer render = new Renderer(bitmap, false);
render.StartRender(page, matrix, null);
// Add the bitmap to image and save the image.
foxit.common.Image image = new foxit.common.Image();
image.AddFrame(bitmap);
image.SaveAs("testpage.jpg");
}
}
Library.Release();
}
}
}
Run the project. In a terminal, navigate to the test_dotnetcore directory, run the command below:
dotnet run
Then the “testpage.jpg” will be generated in the “test_dotnetcore” folder.
Note: Please check whether the “libfsdk.so” and “fsdk_dotnetcore.dll” have been copied to the output directory (“test_dotnetcore/bin/Debug/netcoreapp2.2″). If not, you should put the dynamic libraries to the folder manually.
Mac
What is in the package
Download the Foxit PDF SDK zip for .NET Core (Mac x64 or Mac arm64) package and extract it to a new directory. The release package contains the following folders:
doc: API references, developer guide
examples: sample projects and demos
lib: libraries and license files
res: the default icc profile files used for output preview demo
Note:
You can obtain this package directly from NuGet.
Mac arm64 does not support the PDF preview feature, so the arm library does not include the ‘res’ directory.
How to run a demo
Note: Starting from version 9.0, the version of clang used for building and compiling the Foxit PDF SDK for Mac (x64) has been upgraded from 9.1.0 to 11.0.3.
For Mac x64, before running the demos, please make sure you have installed dotnet 2.1 or higher and configured the .NET Core environment on x64 Mac correctly.
For Mac arm64, before running the demos, please make sure you have installed dotnet 6.0 or higher and configured the .NET Core environment on arm64 Mac correctly.
Foxit PDF SDK for .NET Core (Mac x64 and arm64) provides several simple demos in directory “examples/simple_demo”. All these demos (except compliance, preflight, html2pdf, output preview (only for Mac x64) and dwg2pdf (only for Mac x64) demos) can be run directly in a terminal using the “RunDemo.sh” file in directory “examples/simple_demo”.
Open a terminal, navigate to “examples/simple_demo”, and then run the following command:
Type “./RunDemo.sh all“ to run all the demos.
Type “./RunDemo.sh demo_name“ to run a specific single demo, for example, “./RunDemo.sh bookmark” will only run the bookmark demo.
“examples/simple_demo/input_files” contains all the input files used among these demos. Some demos will generate output files (pdf, text or image files) to a folder named by the project name under “examples/simple_demo/output_files/” folder.
Compliance and Preflight demos
For how to run the compliance and preflight demos, please refer to section “Compliance”.
HTML to PDF demo
For how to run the html2pdf demo, please refer to section “HTML to PDF Conversion”.
Output Preview demo (only for Mac x64)
For how to run the output preview demo, please refer to section “Output Preview”.
DWG to PDF demo (only for Mac x64)
For how to run the dwg2pdf demo, please refer to section “DWG to PDF Conversion”.
How to create a simple project
In this section, we will show you how to use Foxit PDF SDK for .NET Core to create a simple project that renders the first page of a PDF to a bitmap and saves it as a JPG image. The project will take .NET Core 6.0 for example. To create the project, please follow the steps below:
Create a new .NET Core Console App (with C#) named “test_dotnetcore”. Open a terminal, navigate to the directory where you wish to create your project, and run the following command:
dotnet new console -lang C# -o test_dotnetcore
Then, the test_dotnetcore project will be shown as the Figure 2-12.
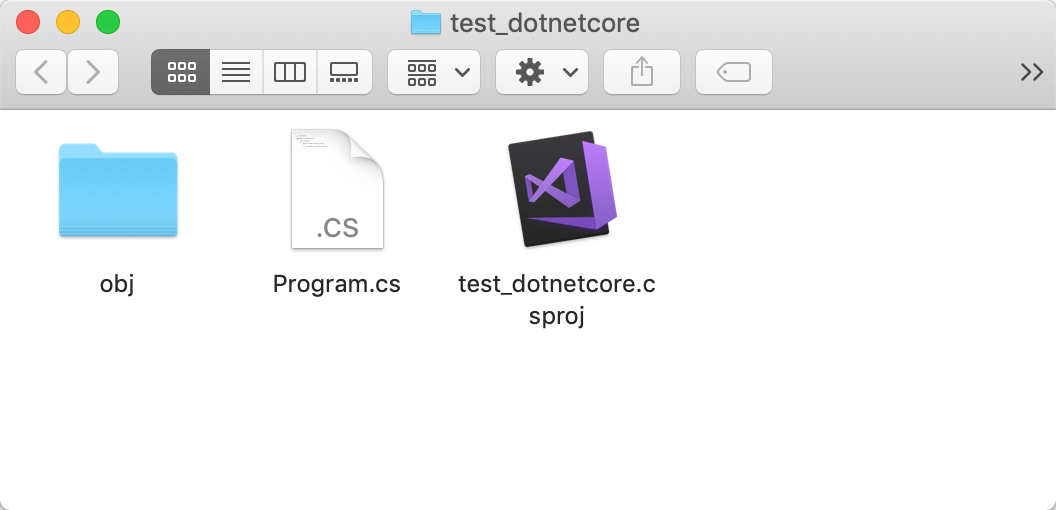
Figure 2-12
For Mac x64, copy the “lib” folder from the “foxitpdfsdk_11_0_mac_dotnetcore” folder to the project “test_dotnetcore” folder.
For Mac arm64, copy the “lib” folder from the “foxitpdfsdk_11_0_mac_arm64_dotnetcore” folder to the project “test_dotnetcore” folder.
Copy a PDF file (“Sample.pdf” for example) to the “test_dotnetcore” folder, which will be used to test the project.
Add references to the “fsdk_dotnetcore.dll”, as well as add “libfsdk.dylib”.
Edit the test_dotnetcore.csproj file and add the following code:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp6.0</TargetFramework>
</PropertyGroup>
<ItemGroup>
<Reference Include="fsdk_dotnetcore">
<HintPath>lib/fsdk_dotnetcore.dll</HintPath>
</Reference>
</ItemGroup>
<ItemGroup>
<FSdkLibSourceFiles Include="lib/libfsdk.dylib" />
</ItemGroup>
<Target Name="PreBuild" BeforeTargets="PreBuildEvent">
<Copy SourceFiles="@(FSdkLibSourceFiles)" DestinationFolder="$(OutputPath)" SkipUnchangedFiles="True" />
</Target>
<ItemGroup>
<None Update="Sample.pdf">
<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>
</None>
</ItemGroup>
</Project>
Open Program.cs and add the below code:
using System;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
namespace test_dotnetcore
{
class Program
{
static void Main(string[] args)
{
// The value of "sn" can be got from "gsdk_sn.txt" (the string after "SN=").
// The value of "key" can be got from "gsdk_key.txt" (the string after "Sign=").
string sn = " ";
string key = " ";
ErrorCode error_code = Library.Initialize(sn, key);
if (error_code != ErrorCode.e_ErrSuccess)
{
return;
}
using (PDFDoc doc = new PDFDoc("Sample.pdf"))
{
error_code = doc.LoadW("");
if (error_code != ErrorCode.e_ErrSuccess)
{
Library.Release();
return;
}
using (PDFPage page = doc.GetPage(0))
{
// Parse page.
page.StartParse((int)foxit.pdf.PDFPage.ParseFlags.e_ParsePageNormal, null, false);
int width = (int)(page.GetWidth());
int height = (int)(page.GetHeight());
Matrix2D matrix = page.GetDisplayMatrix(0, 0, width, height, page.GetRotation());
// Prepare a bitmap for rendering.
foxit.common.Bitmap bitmap = new foxit.common.Bitmap(width, height, foxit.common.Bitmap.DIBFormat.e_DIBArgb, System.IntPtr.Zero, 0);
bitmap.FillRect(0xFFFFFFFF, null);
// Render page
Renderer render = new Renderer(bitmap, false);
render.StartRender(page, matrix, null);
// Add the bitmap to image and save the image.
foxit.common.Image image = new foxit.common.Image();
image.AddFrame(bitmap);
image.SaveAs("testpage.jpg");
}
}
Library.Release();
}
}
}
Run the project. In a terminal, navigate to the test_dotnetcore directory, run the command below:
dotnet run
Then the “testpage.jpg” will be generated in the “test_dotnetcore” folder.
Note: Please check whether the “libfsdk.dylib” and “fsdk_dotnetcore.dll” have been copied to the output directory (“test_dotnetcore/bin/Debug/netcoreapp6.0“). If not, you should put the dynamic libraries to the folder manually.
How to run a simple demo in dotnet 6.0
Foxit PDF SDK for .NET Core (Windows, Linux x64/armv7, and Mac x64) is based on the .NET Core 2.1 while supporting the dotnet 6.0. And then, how to use it in dotnet 6.0? Please refer to the following.
Change the simple demo TargetFramework to dotnet 6.0
Before running the simple demo, open the .csproj file, and configure the TargetFramework to netcoreapp6.0. And then, the simple demo can run in dotnet 6.0. The .csproj file refers to the following XML file.
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp6.0</TargetFramework>
...
</PropertyGroup>
...
</Project>
Windows
Install the dotnet 6.0
1.Install Visual Studio
2.Install .NET Runtime 6.0
Compile and run the project
Refer to the 2.2.2 How to run a demo.
Linux
Install the dotnet 6.0
1.Install .NET Runtime 6.0
Compile and run the project
Refer to the 2.3.2 How to run a demo.
macOS
Install dotnet 6.0 on the system
1.Install .NET Runtime 6.0
Compile and run the project
Refer to the 2.4.2 How to run a demo.
Create a simple project that can switch libraries based on the platform
This section will demonstrate how to create a cross-platform .NET Core project that can switch libraries based on the platform. Same as the previous created projects, we create a simple project that renders the first page of a PDF to a bitmap and saves it as a JPG image. The project will take .NET Core 2.2 for example to switch the libraries of Windows, Linux and Mac x64.
Note: For Mac arm64, you should use .NET Core 6.0 or higher, and then replace the Mac x64 libraries with the Mac arm64 libraries.
To create the project, please follow the steps below:
Create a new .NET Core Console App (with C#) named “test_autodotnetcore”. Open a command prompt or a terminal, navigate to the directory where you wish to create your project, and run the following command:
dotnet new console -lang C# -o test_autodotnetcore
In the project “test_autodotnetcore” folder, create a “lib” folder, and then create three folders (for example, naming “win”, “linux” and “osx”) under the “lib” folder, which are used to place the libraries for specific platforms.
Copy the folders under the “lib” folder of “foxitpdfsdk_11_0_win_dotnetcore”, and then paste them into the “test_autodotnetcore/lib/win” folder.
Copy the libraries under the “lib” folder of “foxitpdfsdk_11_0_linux64_dotnetcore”, and then paste them into the “test_autodotnetcore/lib/linux” folder.
Copy the libraries under the “lib” folder of “foxitpdfsdk_11_0_mac_dotnetcore” for Mac x64, and then paste them into the “test_autodotnetcore/lib/osx” folder.
Copy the trial license key files “gsdk_key.txt” and “gsdk_sn.txt” under the “lib” folder of any platform package, and paste them into “test_autodotnetcore/lib” folder.
After done, the structure of the “test_autodotnetcore” will look like the Figure 2-13 :
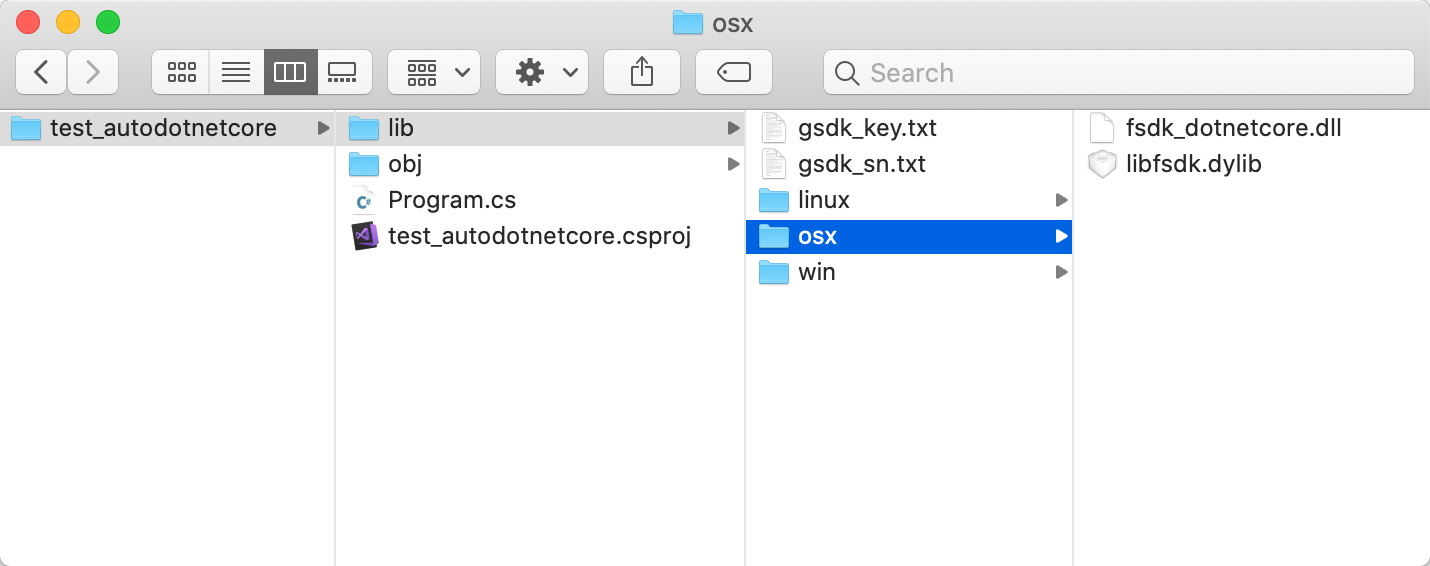
Figure 2-13
Copy a PDF file (“Sample.pdf” for example) to the “test_autodotnetcore” folder, which will be used to test the project.
Add references to the “fsdk_dotnetcore.dll”, as well as add platform library, for example, “libfsdk.dylib”.
Edit the test_autodotnetcore.csproj file and add the following code:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp2.2</TargetFramework>
<AppendTargetFrameworkToOutputPath>False</AppendTargetFrameworkToOutputPath>
<RuntimeIdentifiers>win-x86;win-x64;linux-x64;osx-x64</RuntimeIdentifiers>
</PropertyGroup>
<PropertyGroup Condition="'$(Configuration)|$(Platform)'=='Debug|AnyCPU'">
<OutputPath>bin/</OutputPath>
</PropertyGroup>
<PropertyGroup Condition="'$(Configuration)|$(Platform)'=='Release|AnyCPU'">
<OutputPath>bin/</OutputPath>
</PropertyGroup>
<!-- Include the platform library based on the platform -->
<ItemGroup Condition="$([MSBuild]::IsOsPlatform(Windows))">
<Content Include="$(OutputPath)fsdk.dll" Link="fsdk.dll">
<CopyToOutputDirectory>Always</CopyToOutputDirectory>
<Pack>True</Pack>
<PackagePath>lib\netstandard2.2</PackagePath>
</Content>
</ItemGroup>
<ItemGroup Condition="$([MSBuild]::IsOsPlatform(Linux))">
<Content Include="$(OutputPath)libfsdk.so" Link="libfsdk.so">
<CopyToOutputDirectory>Always</CopyToOutputDirectory>
<Pack>True</Pack>
<PackagePath>lib/netstandard2.2</PackagePath>
</Content>
</ItemGroup>
<ItemGroup Condition="$([MSBuild]::IsOsPlatform(OSX))">
<Content Include="$(OutputPath)libfsdk.dylib" Link="libfsdk.dylib">
<CopyToOutputDirectory>Always</CopyToOutputDirectory>
<Pack>True</Pack>
<PackagePath>lib/netstandard2.2</PackagePath>
</Content>
</ItemGroup>
<!-- Remove the "lib" directory from the project, because -->
<!-- it is in the same directory with the "test_autodotnetcore.csproj" file -->
<ItemGroup>
<None Remove="lib\**" />
</ItemGroup>
<!-- Reference the "fsdk_dotnetcore.dll" based on the platform -->
<ItemGroup>
<Reference Include="fsdk_dotnetcore">
<HintPath>$(OutputPath)fsdk_dotnetcore.dll</HintPath>
</Reference>
</ItemGroup>
<ItemGroup Condition="$([MSBuild]::IsOsPlatform(Windows)) And '$(Platform)'=='x86'">
<FSdkLibSourceFiles Include="lib\win\x86_vc17\*fsdk*.*" />
</ItemGroup>
<ItemGroup Condition="$([MSBuild]::IsOsPlatform(Windows)) And ('$(Platform)'=='AnyCPU' Or '$(Platform)'=='x64')">
<FSdkLibSourceFiles Include="lib\win\x64_vc17\*fsdk*.*" />
</ItemGroup>
<ItemGroup Condition="$([MSBuild]::IsOsPlatform(Linux))">
<FSdkLibSourceFiles Include="lib\linux\*fsdk*.*" />
</ItemGroup>
<ItemGroup Condition="$([MSBuild]::IsOsPlatform(OSX))">
<FSdkLibSourceFiles Include="lib\osx\*fsdk*.*" />
</ItemGroup>
<Target Name="PreBuild" BeforeTargets="PreBuildEvent">
<Copy SourceFiles="@(FSdkLibSourceFiles)" DestinationFolder="$(OutputPath)" SkipUnchangedFiles="True" />
</Target>
<!-- Copy the PDF file to the execution directory -->
<ItemGroup>
<None Update="Sample.pdf">
<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>
</None>
</ItemGroup>
</Project>
Note: If the “lib” folder is in the same directory with the “test_autodotnetcore.csproj” file, you should add the code below to exclude the libraries in the “lib” folder:
<ItemGroup> <None Remove="lib\**" /> </ItemGroup>
Open Program.cs and add the below code:
using System;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
namespace test_dotnetcore
{
class Program
{
static void Main(string[] args)
{
// The value of "sn" can be got from "gsdk_sn.txt" (the string after "SN=").
// The value of "key" can be got from "gsdk_key.txt" (the string after "Sign=").
string sn = " ";
string key = " ";
ErrorCode error_code = Library.Initialize(sn, key);
if (error_code != ErrorCode.e_ErrSuccess)
{
return;
}
using (PDFDoc doc = new PDFDoc("Sample.pdf"))
{
error_code = doc.LoadW("");
if (error_code != ErrorCode.e_ErrSuccess)
{
Library.Release();
return;
}
using (PDFPage page = doc.GetPage(0))
{
// Parse page.
page.StartParse((int)foxit.pdf.PDFPage.ParseFlags.e_ParsePageNormal, null, false);
int width = (int)(page.GetWidth());
int height = (int)(page.GetHeight());
Matrix2D matrix = page.GetDisplayMatrix(0, 0, width, height, page.GetRotation());
// Prepare a bitmap for rendering.
foxit.common.Bitmap bitmap = new foxit.common.Bitmap(width, height, foxit.common.Bitmap.DIBFormat.e_DIBArgb, System.IntPtr.Zero, 0);
bitmap.FillRect(0xFFFFFFFF, null);
// Render page
Renderer render = new Renderer(bitmap, false);
render.StartRender(page, matrix, null);
// Add the bitmap to image and save the image.
foxit.common.Image image = new foxit.common.Image();
image.AddFrame(bitmap);
image.SaveAs("testpage.jpg");
}
}
Library.Release();
}
}
}
Run the project. In a command prompt or a terminal, navigate to the test_autodotnetcore directory, type the commands below to build and run the project:
Build the test_autodotnetcore.csproj:
dotnet build test_autodotnetcore.csproj // for 64-bit Windows, Mac, and Linux
Note: This project uses 64-bit libraries by default. If you want to build 32-bit libraries, you can use the command “dotnet build test_autodotnetcore.csproj –p:Platform=x86“.
Run the project:
dotnet run
Then the “testpage.jpg” will be generated in the “test_autodotnetcore” or “test_autodotnetcore/bin” folder.
Working with SDK API
In this section, we will introduce a set of major features and list some examples for each feature to show you how to integrate Foxit PDF SDK for .NET Core into the projects on Windows, Linux and Mac platforms. You can refer to the API reference [2] to get more details about the APIs used in all of the examples.
Initialize Library
It is necessary for applications to initialize Foxit PDF SDK before calling any APIs. The function foxit.common.Library.Initialize is provided to initialize Foxit PDF SDK. A license should be purchased for the application and pass unlock key and code to get proper support. When there is no need to use Foxit PDF SDK any more, please call function foxit.common.Library.Release to release it.
Note: The parameter “sn” can be found in the “gsdk_sn.txt” (the string after “SN=”) and the “key” can be found in the “gsdk_key.txt” (the string after “Sign=”).
Example:
How to initialize Foxit PDF SDK
using foxit.common; string sn = " "; string key = " "; ErrorCode error_code = Library.Initialize(sn, key); if (error_code != ErrorCode.e_ErrSuccess) return; ...
Document
A PDF document object can be constructed with an existing PDF file from file path, memory buffer, a custom implemented ReaderCallback object and an input file stream. Then call function PDFDoc.Load or PDFDoc.StartLoad to load document content. A PDF document object is used for document level operation, such as opening and closing files, getting page, annotation, metadata and etc.
Example:
How to create a PDF document from scratch
using foxit.pdf; ... PDFDoc doc = new PDFDoc();
Note: It creates a new PDF document without any pages.
How to load an existing PDF document from file path
using foxit.pdf;
using foxit.common;
...
PDFDoc doc = new PDFDoc("Sample.pdf");
error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess) return;
How to load an existing PDF document from a memory buffer
using foxit;
using foxit.pdf;
using foxit.common;
...
byte[] byte_buffer = File.ReadAllBytes(input_file);
IntPtr buffer = System.Runtime.InteropServices.Marshal.AllocHGlobal(byte_buffer.Length);
try
{
System.Runtime.InteropServices.Marshal.Copy(byte_buffer, 0, buffer, byte_buffer.Length);
PDFDoc doc = new PDFDoc(buffer, (uint)byte_buffer.Length);
error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess) return;
...
}
catch (foxit.PDFException e)
{
Console.WriteLine("Error:{0}", e.GetErrorCode());
}
catch (System.Exception e)
{
Console.WriteLine(e.Message);
}
finally
{
System.Runtime.InteropServices.Marshal.FreeHGlobal(buffer);
}
How to load an existing PDF document from a file read callback object
using foxit.pdf;
using foxit.common;
...
class FileReader : FileReaderCallback
{
private FileStream file_ = null;
private long offset_ = 0;
public FileReader(long offset)
{
this.offset_ = offset;
}
public Boolean LoadFile(String file_path)
{
file_ = new FileStream(file_path, FileMode.OpenOrCreate);
return true;
}
public override long GetSize()
{
return this.offset_;
}
public override bool ReadBlock(IntPtr buffer, long offset, uint size)
{
int read_size = 0;
file_.Seek(offset, SeekOrigin.Begin);
byte[] array = new byte[size + 1];
read_size = file_.Read(array, 0, (int)size);
Marshal.Copy(array, 0, buffer, (int)size);
return read_size == size ? true : false;
}
public override void Release()
{
this.file_.Close();
}
}
...
FileReader file_reader = new FileReader(offset);
file_reader.LoadFile(file_name);
PDFDoc doc_real = new PDFDoc(file_reader, false)
error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess) return;
...
How to load PDF document and get the first page of the PDF document
using foxit.pdf;
using foxit.common;
...
PDFDoc doc = new PDFDoc("Sample.pdf");
error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess) return;
...
// Get the first page of the document.
PDFPage page = doc.GetPage(0);
// Parse page.
page.StartParse((int)foxit.pdf.PDFPage.ParseFlags.e_ParsePageNormal, null, false);
...
How to save a PDF to a file
using foxit.pdf;
using foxit.common;
...
PDFDoc doc = new PDFDoc("Sample.pdf");
error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess) return;
...
// Do operations for the PDF document.
...
// Save the changes for the PDF document.
string newPdf = "the output path for the saved PDF";
doc.SaveAs(newPdf, (int)PDFDoc.SaveFlags.e_SaveFlagNoOriginal);
How to save a document into memory buffer by FileWriterCallback
using foxit.pdf;
using foxit.common;
using foxit.common.fxcrt;
using System.IO;
using System.Runtime.InteropServices;
...
class FileWriter : FileWriterCallback
{
private MemoryStream memoryfilestream = new MemoryStream();
public FileWriter()
{
}
public override long GetSize()
{
return this.memoryfilestream.Length;
}
public override bool WriteBlock(IntPtr pData, long offset, uint size)
{
byte[] ys = new byte[size];
Marshal.Copy(pData, ys, 0, (int)size);
memoryfilestream.Write(ys, 0, (int)size);
return true;
}
public override bool Flush()
{
return true;
}
public override void Release()
{
}
}
...
FileWriter fileWriter = new FileWriter();
// Assuming PDFDoc doc has been loaded.
...
doc.StartSaveAs(fileWriter, (int) PDFDoc.SaveFlags.e_SaveFlagNoOriginal,null);
...
Page
PDF Page is the basic and important component of PDF Document. A PDFPage object is retrieved from a PDF document by function PDFDoc.GetPage. Page level APIs provide functions to parse, render, edit (includes creating, deleting and flattening) a page, retrieve PDF annotations, read and set the properties of a page, and etc. For most cases, A PDF page needs to be parsed before it is rendered or processed.
Example:
How to get page size
using foxit.pdf; using foxit.common; ... // Assuming PDFPage page has been loaded and parsed. ... int width = (int)(page.GetWidth()); int height = (int)(page.GetHeight()); ...
How to calculate bounding box of page contents
using foxit.pdf; ... // Assuming PDFPage page has been loaded and parsed. ... RectF ret = page.CalcContentBBox(PDFPage.CalcMarginMode.e_CalcContentsBox); ...
How to create a PDF page and set the size
using foxit.pdf; ... // Assuming PDFDoc doc has been loaded. PDFPage page = doc.InsertPage(index, PageWidth, PageHeight);
How to delete a PDF page
using foxit.pdf; ... // Assuming PDFDoc doc has been loaded. // Remove a PDF page by page index. doc.RemovePage(index); // Remove a specified PDF page. doc.RemovePage(page); ...
How to flatten a PDF page
using foxit.pdf; ... // Assuming PDFPage page has been loaded and parsed. // Flatten all contents of a PDF page. page.Flatten(true, (int)PDFPage.FlattenOptions.e_FlattenAll); // Flatten a PDF page without annotations. page.Flatten(true, (int)PDFPage.FlattenOptions.e_FlattenNoAnnot); // Flatten a PDF page without form controls. page.Flatten(true, (int)PDFPage.FlattenOptions.e_FlattenNoFormControl); // Flatten a PDF page without annotations and form controls (Equals to nothing to be flattened). page.Flatten(true, (int)(PDFPage.FlattenOptions.e_FlattenNoAnnot | PDFPage.FlattenOptions.e_FlattenNoFormControl)); ...
How to get and set page thumbnails in a PDF document
using foxit.pdf; ... // Assuming PDFPage page has been loaded and parsed. // Get page thumbnails. page.LoadThumbnail(); // Set thumbnails to the page. // Assuming Bitmap bitmap has been created. page.SetThumbnail(bitmap); ...
Render
PDF rendering is realized through the Foxit renderer, a graphic engine that is used to render page to a bitmap or platform graphics device. Foxit PDF SDK provides APIs to set rendering options/flags, for example set flag to decide whether to render form fields and signature, whether to draw image anti-aliasing and path anti-aliasing. To do rendering, you can use the following APIs:
To render page and annotations, first use function Renderer.SetRenderContentFlags to decide whether to render page and annotation both or not, and then use function Renderer.StartRender to do the rendering. Function Renderer.StartQuickRender can also be used to render page but only for thumbnail purpose.
To render a single annotation, use function Renderer.RenderAnnot.
To render on a bitmap, use function Renderer.StartRenderBitmap.
To render a reflowed page, use function Renderer.StartRenderReflowPage.
Widget annotation is always associated with form field and form control in Foxit PDF SDK. For how to render widget annotations, here is a recommended flow:
After loading a PDF page, first render the page and all annotations in this page (including widget annotations).
Then, if use pdf.interform.Filler object to fill the form, the function pdf.interform.Filler.Render should be used to render the focused form control instead of the function Renderer.RenderAnnot.
Example:
How to render a page to a bitmap
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; // Assuming PDFPage page has been loaded and parsed. int width = (int)(page.GetWidth()); int height = (int)(page.GetHeight()); Matrix2D matrix = page.GetDisplayMatrix(0, 0, width, height, page.GetRotation()); // Prepare a bitmap for rendering. foxit.common.Bitmap bitmap = new foxit.common.Bitmap(width, height, foxit.common.Bitmap.DIBFormat.e_DIBArgb, System.IntPtr.Zero, 0); bitmap.FillRect(0xFFFFFFFF, null); // Render page. Renderer render = new Renderer(bitmap, false); render.StartRender(page, matrix, null); ...
How to render page and annotation
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; // Assuming PDFPage page has been loaded and parsed. ... int width = (int)(page.GetWidth()); int height = (int)(page.GetHeight()); Matrix2D matrix = page.GetDisplayMatrix(0, 0, width, height, page.GetRotation()); // Prepare a bitmap for rendering. foxit.common.Bitmap bitmap = new foxit.common.Bitmap(width, height, foxit.common.Bitmap.DIBFormat.e_DIBArgb, System.IntPtr.Zero, 0); bitmap.FillRect(0xFFFFFFFF, null); // Render page Renderer render = new Renderer(bitmap, false); render.SetRenderContentFlags((int)Renderer.ContentFlag.e_RenderAnnot | (int)Renderer.ContentFlag.e_RenderPage); render.StartRender(page, matrix, null); ...
Attachment
In Foxit PDF SDK, attachments are only referred to attachments of documents rather than file attachment annotation, which allow whole files to be encapsulated in a document, much like email attachments. PDF SDK provides applications APIs to access attachments such as loading attachments, getting attachments, inserting/removing attachments, and accessing properties of attachments.
Example:
How to export the embedded attachment file from a PDF and save it as a single file
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.objects;
// Assuming PDFDoc doc has been loaded.
string text_path = "The input path of the attached file you need to insert";
using (Attachments attachments = new Attachments(doc, new PDFNameTree()))
{
int count = attachments.GetCount();
for (int i = 0; i < count; i++)
{
string key = attachments.GetKey(i);
using (FileSpec file_spec = attachments.GetEmbeddedFile(key))
{
if (!file_spec.IsEmpty())
{
string name = file_spec.GetFileName();
if (file_spec.IsEmbedded())
{
String exFilePath = "output_directory";
file_spec.ExportToFile(exFilePath);
}
}
}
}
...
How to remove all the attachments of a PDF
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.objects;
// Assuming PDFDoc doc has been loaded.
...
using (Attachments attachments = new Attachments(doc, new PDFNameTree()))
{
int count = attachments.GetCount();
for (int i = 0; i < count; i++)
{
string key = attachments.GetKey(i);
attachment.RemoveEmbeddedFile(key);
}
}
...
Text Page
Foxit PDF SDK provides APIs to extract, select, search and retrieve text in PDF documents. PDF text contents are stored in TextPage objects which are related to a specific page. TextPage class can be used to retrieve information about text in a PDF page, such as single character, single word, text content within specified character range or rectangle and so on. It also can be used to construct objects of other text related classes to do more operations for text contents or access specified information from text contents:
To search text in text contents of a PDF page, construct a TextSearch object with TextPage object.
To access text such like hypertext link, construct a PageTextLinks object with TextPage object.
Example:
How to extract text from a PDF page
using foxit.common;
using foxit.pdf;
...
// Assuming PDFPage page has been loaded and parsed.
using (var text_page = new TextPage(page, (int)TextPage.TextParseFlags.e_ParseTextNormal))
{
int count = text_page.GetCharCount();
if (count > 0)
{
String chars = text_page.GetChars(0, count);
writer.Write(chars);
}
}
...
How to get the text within a rectangle area in a PDF
using foxit.common; using foxit.pdf; using foxit.common.fxcrt; ... RectF rect = new RectF(100, 50, 220, 100); TextPage text_page = new TextPage(page, (int)foxit.pdf.TextPage.TextParseFlags.e_ParseTextNormal); String str_text = text_page.GetTextInRect(rect); ...
Text Search
Foxit PDF SDK provides APIs to search text in a PDF document, a XFA document, a text page or in a PDF annotation’s appearance. It offers functions to do a text search and get the searching result:
To specify the searching pattern and options, use functions TextSearch.SetPattern, TextSearch.SetStartPage (only useful for a text search in PDF document), TextSearch.SetEndPage (only useful for a text search in PDF document) and TextSearch.SetSearchFlags.
To do the searching, use function TextSearch.FindNext or TextSearch.FindPrev.
To get the searching result, use function TextSearch.GetMatchXXX().
Example:
How to search a text pattern in a page
using foxit.common;
using foxit.pdf;
...
// Assuming PDFDoc doc has been loaded.
using (TextSearch search = new TextSearch(doc, null, (int)TextPage.TextParseFlags.e_ParseTextNormal))
{
int start_index = 0;
int end_index = doc.GetPageCount() - 1;
search.SetStartPage(0);
search.SetEndPage(doc.GetPageCount() - 1);
String pattern = "Foxit";
search.SetPattern(pattern);
Int32 flags = (int)TextSearch.SearchFlags.e_SearchNormal;
search.SetSearchFlags(flags);
int match_count = 0;
while (search.FindNext())
{
RectFArray rect_array = search.GetMatchRects();
match_count++;
}
...
Search and Replace
The Search and Replace feature allows you to search for specific text content within a PDF document and replace it with new content.
System requirements
Platform: Windows, Linux, Mac
Programming Language: C, C++, Java, C#, Python, Objective-C, Node.js, Go
License Key requirement: ‘AdvEdit’ module permission in the license key
SDK Version: Foxit PDF SDK (C, C++, C#, Java, Python, Objective-C) 9.0 or higher; Foxit PDF SDK (Node.js) 10.0 or higher; Foxit PDF SDK (Go) 11.0
How to work with the search and replace function
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.addon.pageeditor;
…
using (PDFDoc doc = new PDFDoc(input_file))
{
error_code = doc.Load(null);
// Instantiate a TextSearchReplace object.
using (TextSearchReplace searchreplace = new TextSearchReplace(doc))
// Configure search options, match whole words only, whether to set match only whole words and match case.
using (FindOption find_option = new FindOption(true, true))
using (ReplaceCallbackImpl replace_callback = new ReplaceCallbackImpl())
// Set replacing callback function.
searchreplace.SetReplaceCallback(replace_callback);
// Set keywords and page index to do searching and replacing.
searchreplace.SetPattern("PDF", 0, find_option);
// Replace with new text.
while (searchreplace.ReplaceNext("PDC") == true) {}
}
Text Link
In a PDF page, some text contents that represent a hypertext link to a website or a resource on the intent, or an email address are the same with common texts. Prior to text link processing, user should first call PageTextLinks.GetTextLink to get a textlink object.
Example:
How to retrieve hyperlinks in a PDF page
using foxit.common; using foxit.pdf; ... // Assuming PDFPage page has been loaded and parsed. // Get the text page object. TextPage text_page = new TextPage(page, (int)foxit.pdf.TextPage.TextParseFlags.e_ParseTextNormal); PageTextLinks page_textlinks = new PageTextLinks(text_page); TextLink text_link = page_textlinks.GetTextLink(index); // specify an index. string str_url = text_link.GetURI(); ...
Bookmark
Foxit PDF SDK provides navigational tools called Bookmarks to allow users to quickly locate and link their point of interest within a PDF document. PDF bookmark is also called outline, and each bookmark contains a destination or actions to describe where it links to. It is a tree-structured hierarchy, so function pdf.PDFDoc.GetRootBookmark must be called first to get the root of the whole bookmark tree before accessing to the bookmark tree. Here, “root bookmark” is an abstract object which can only have some child bookmarks without next sibling bookmarks and any data (includes bookmark data, destination data and action data). It cannot be shown on the application UI since it has no data. Therefore, a root bookmark can only call function Bookmark.GetFirstChild.
After the root bookmark is retrieved, following functions can be called to access other bookmarks:
To access the parent bookmark, use function Bookmark.GetParent.
To access the first child bookmark, use function Bookmark.GetFirstChild.
To access the next sibling bookmark, use function Bookmark.GetNextSibling.
To insert a new bookmark, use function Bookmark.Insert.
To move a bookmark, use function Bookmark.MoveTo.
Example:
How to find and list all bookmarks of a PDF
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.actions;
...
//Assuming PDFDoc doc has been loaded.
...
Bookmark root = doc.GetRootBookmark();
Bookmark first_bookmark = root.GetFirstChild();
if (first_bookmark != null)
{
TraverseBookmark(first_bookmark, 0);
}
Private void TraverseBookmark(Bookmark root, int iLevel)
{
if (root != null)
{
Bookmark child = root.GetFirstChild();
while (child != null)
{
TraverseBookmark(child, iLevel + 1);
child = child.GetNextSibling();
}
}
}
...
How to insert a new bookmark
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.actions;
// Assuming PDFDoc doc has been loaded.
Bookmark root = doc.GetRootBookmark();
if (root.IsEmpty())
{
root = doc.CreateRootBookmark();
}
using (Destination dest = Destination.CreateFitPage(doc, 0))
{
string ws_title = string.Format("A bookmark to a page (index: {0})", 0);
Bookmark child;
using (child = root.Insert(ws_title, Bookmark.Position.e_PosLastChild))
{
child.SetDestination(dest);
child.SetColor(0xF68C21);
}
}
How to create a table of contents based on bookmark information in PDFs
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.actions;
static void AddTOCToPDF(PDFDoc doc)
{
//Set the table of contents configuration.
using (var intarray = new Int32Array())
{
int depth = doc.GetBookmarkLevelDepth();
if (depth > 0)
{
for (int i = 1; i <= depth; i++)
{
intarray.Add(i);
}
}
string title = "";
using (var toc_config = new TableOfContentsConfig(title, intarray, true, false))
{
//Add the table of contents
doc.AddTableOfContents(toc_config);
}
}
}
Form (AcroForm)
PDF currently supports two different forms for gathering information interactively from the user – AcroForms and XFA forms. Acroforms are the original PDF-based fillable forms, based on the PDF architecture. Foxit PDF SDK provides APIs to view and edit form field programmatically. Form fields are commonly used in PDF documents to gather data. The Form class offers functions to retrieve form fields or form controls, import/export form data and other features, for example:
To retrieve form fields, please use functions Form.GetFieldCount and Form.GetField.
To retrieve form controls from a PDF page, please use functions Form.GetControlCount and Form.GetControl.
To import form data from an XML file, please use function Form.ImportFromXML; to export form data to an XML file, please use function Form.ExportToXML.
To retrieve form filler object, please use function Form.GetFormFiller.
To import form data from a FDF/XFDF file or export such data to a FDF/XFDF file, please refer to functions pdf.PDFDoc.ImportFromFDF and pdf.PDFDoc.ExportToFDF.
Example:
How to load the forms in a PDF
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.interform;
using foxit.pdf.annots;
...
// Assuming PDFDoc doc has been loaded.
Boolean hasForm = doc.HasForm();
If(hasForm)
Form form = new Form(doc);
...
How to count form fields and get the properties
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.interform;
using foxit.pdf.annots;
...
// Assuming PDFDoc doc has been loaded.
Form form = new Form(doc);
int count = form.GetFieldCount("");
for (int i = 0; i < count; i++)
{
Field field = form.GetField(i, "");
Field.Type type = field.GetType();
WString org_alternateName = field.GetAlternateName();
field.SetAlternateName("signature");
}
How to export the form data in a PDF to a XML file
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.interform;
using foxit.pdf.annots;
...
// Assuming PDFDoc doc has been loaded.
Boolean hasForm = doc.HasForm();
If(hasForm)
Form form = new Form(doc);
...
form.ExportToXML(XMLFilePath);
...
How to import form data from a XML file
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.interform;
using foxit.pdf.annots;
...
// Assuming PDFDoc doc has been loaded.
Boolean hasForm = doc.HasForm();
If(hasForm)
Form form = new Form(doc);
...
form.ImportFromXML(XMLFilePath);
...
How to get and set the properties of form fields
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.interform;
using foxit.pdf.annots;
...
// Assuming PDFDoc doc has been loaded.
Boolean hasForm = doc.HasForm();
If(hasForm)
Form form = new Form(doc);
Field field = form.GetField(0, "Text Field0");
field.GetAlignment();
field.GetAlternateName();
field.SetAlignment(Alignment.e_AlignmentLeft);
field.SetValue("3");
...
How to get coordinates of a form field
Load PDF file by PDFDoc.
Traverse the form fields of the PDFDoc to get the field object of form.
Traverse the form controls of the field object to get the form control object.
Get the related widget annotation object by form control.
Call the GetRect of the widget annotation object to get the coordinate of the form.
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.interform;
using foxit.pdf.annots;
...
using (PDFDoc doc = new PDFDoc(input_file))
{
ErrorCode error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess)
{
Console.WriteLine("[Failed] Cannot load PDF document: " + input_file + ".\r\nError Code: " + error_code + "\r\n");
return;
}
if (!doc.HasForm()) return;
using (Form form = new Form(doc))
{
for (int i = 0; i < form.GetFieldCount(null); i++)
{
using (Field field = form.GetField(i, null))
{
if (field.IsEmpty()) continue;
for (int j = 0; j < field.GetControlCount(); j++)
{
using (Control control = field.GetControl(j))
using (Widget widget = control.GetWidget())
//Get rectangle of the annot widget.
using (RectF rect = widget.GetRect()){}
}
}
}
}
}
...
XFA Form
XFA (XML Forms Architecture) forms are XML-based forms, wrapped inside a PDF. The XML Forms Architecture provides a template-based grammar and a set of processing rules that allow uses to build interactive forms. At its simplest, a template-based grammar defines fields in which a user provides data.
Foxit PDF SDK provides APIs to render the XFA form, fill the form, export or import form’s data.
Note:
Foxit PDF SDK provides two callback classes foxit.addon.xfa.AppProviderCallback and foxit.addon.xfa.DocProviderCallback to represent the callback objects as an XFA document provider and an XFA application provider respectively. All the functions in those classes are used as callback functions. Pure virtual functions should be implemented by users.
To use the XFA form feature, please make sure the license key has the permission of the ‘XFA’ module
Example:
How to load XFADoc and represent an Interactive XFA form
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.addon;
using foxit.addon.xfa;
...
// Implement from AppProviderCallback
CFS_XFAAppHandler pXFAAppHandler = new CFS_XFAAppHandler();
Library.RegisterXFAAppProviderCallback(pXFAAppHandler);
string input_file = input_path + "xfa_dynamic.pdf";
using (PDFDoc doc = new PDFDoc(input_file))
{
error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess)
{
Console.WriteLine("The PDFDoc [{0}] Error: {1}\n", input_file, error_code);
Library.Release();
return;
}
// Implement from DocProviderCallback
CFS_XFADocHandler pXFADocHandler = new CFS_XFADocHandler();
using (XFADoc xfa_doc = new XFADoc(doc, pXFADocHandler))
{
...
}
}
How to export and import XFA form data
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.addon;
using foxit.addon.xfa;
...
// Assuming FSXFADoc xfa_doc has been loaded.
...
xfa_doc.ExportData("xfa_form.xml", XFADoc.ExportDataType.e_ExportDataTypeXML);
xfa_doc.ResetForm();
doc.SaveAs("xfa_dynamic_resetform.pdf", (int)foxit.pdf.PDFDoc.SaveFlags.e_SaveFlagNormal);
xfa_doc.ImportData(output_path + "xfa_form.xml");
doc.SaveAs("xfa_dynamic_importdata.pdf", (int)foxit.pdf.PDFDoc.SaveFlags.e_SaveFlagNormal);
...
Form Design
Fillable PDF forms (AcroForm) are especially convenient for preparation of various applications, such as taxes and other government forms. Form design provides APIs to add or remove form fields (Acroform) to or from a PDF file. Designing a form from scratch allows developers to create the exact content and layout of the form they want.
Example:
How to add a text form field to a PDF
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; using foxit.pdf.interform; using foxit.pdf.annots; using foxit.pdf.actions; ... // Assuming PDFDoc doc has been loaded. Control control = form.AddControl(page, "Text Field0", Field.Type.e_TypeTextField, new RectF(50f, 600f, 90f, 640f)) ...
How to remove a text form field from a PDF
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; using foxit.pdf.interform; using foxit.pdf.annots; using foxit.pdf.actions; ... // Assuming PDFDoc doc has been loaded. Field field = form.GetField(0, "Text Field0"); form.RemoveField(field); ......
Annotations
General
An annotation associates an object such as note, line, and highlight with a location on a page of a PDF document. It provides a way to interact with users by means of the mouse and keyboard. PDF includes a wide variety of standard annotation types as listed in Table 3-1. Among these annotation types, many of them are defined as markup annotations for they are used primarily to mark up PDF documents. These annotations have text that appears as part of the annotation and may be displayed in other ways by a conforming reader, such as in a Comments pane. The ‘Markup’ column Table 3-1 shows whether an annotation is a markup annotation.
Foxit PDF SDK supports most annotation types defined in PDF reference [1]. Foxit PDF SDK provides APIs of annotation creation, properties access and modification, appearance setting and drawing.
Table 3-1
| Annotation type | Description | Markup | Supported by SDK |
| Text(Note) | Text annotation | Yes | Yes |
| Link | Link Annotations | No | Yes |
| FreeText (TypeWriter/TextBox/Callout) | Free text annotation | Yes | Yes |
| Line | Line annotation | Yes | Yes |
| Square | Square annotation | Yes | Yes |
| Circle | Circle annotation | Yes | Yes |
| Polygon | Polygon annotation | Yes | Yes |
| PolyLine | PolyLine annotation | Yes | Yes |
| Highlight | Highlight annotation | Yes | Yes |
| Underline | Underline annotation | Yes | Yes |
| Squiggly | Squiggly annotation | Yes | Yes |
| StrikeOut | StrikeOut annotation | Yes | Yes |
| Stamp | Stamp annotation | Yes | Yes |
| Caret | Caret annotation | Yes | Yes |
| Ink(pencil) | Ink annotation | Yes | Yes |
| Popup | Popup annotation | No | Yes |
| File Attachment | FileAttachment annotation | Yes | Yes |
| Sound | Sound annotation | Yes | No |
| Movie | Movie annotation | No | No |
| Widget* | Widget annotation | No | Yes |
| Screen | Screen annotation | No | Yes |
| PrinterMark | PrinterMark annotation | No | No |
| TrapNet | Trap network annotation | No | No |
| Watermark* | Watermark annotation | No | Yes |
| 3D | 3D annotation | No | No |
| Redact | Redact annotation | Yes | Yes |
Note:
The annotation types of widget and watermark are special. They aren’t supported in the module of ‘Annotation’. The type of widget is only used in the module of ‘form filler’ and the type of watermark only in the module of ‘watermark’.
Foxit SDK supports a customized annotation type called PSI (pressure sensitive ink) annotation that is not described in PDF reference [1]. Usually, PSI is for handwriting features and Foxit SDK treats it as PSI annotation so that it can be handled by other PDF products.
Example:
How to add a link annotation to a PDF page
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; using foxit.pdf.graphics; using foxit.pdf.annots; using foxit.pdf.actions; ... // Assuming PDFPage page has been loaded and parsed. Annot annot = page.AddAnnot(Annot.Type.e_Link, new RectF(350, 350, 380, 400)) Link link = new Link(annot); link.SetHighlightingMode(Annot.HighlightingMode.e_HighlightingToggle); // Appearance should be reset. link.ResetAppearanceStream(); ...
How to add a highlight annotation to a page and set the related annotation properties
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.graphics;
using foxit.pdf.annots;
using foxit.pdf.actions;
...
// Assuming PDFPage page has been loaded and parsed.
// Add highlight annotation.
Annot annot = page.AddAnnot(Annot.Type.e_Highlight, new RectF(10, 450, 100, 550));
Highlight highlight = new Highlight(annot);
highlight.SetContent("Highlight");
QuadPoints quad_points = new QuadPoints();
quad_points.first = new foxit.common.fxcrt.PointF(10, 500);
quad_points.second = new foxit.common.fxcrt.PointF(90, 500);
quad_points.third = new foxit.common.fxcrt.PointF(10, 480);
quad_points.fourth = new foxit.common.fxcrt.PointF(90, 480);
QuadPointsArray quad_points_array = new QuadPointsArray();
quad_points_array.Add(quad_points);
highlight.SetQuadPoints(quad_points_array);
highlight.SetSubject("Highlight");
highlight.SetTitle("Foxit SDK");
highlight.SetCreationDateTime(GetLocalDateTime());
highlight.SetModifiedDateTime(GetLocalDateTime());
highlight.SetUniqueID(RandomUID());
// Appearance should be reset.
highlight.ResetAppearanceStream();
...
How to set the popup information when creating markup annotations
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.graphics;
using foxit.pdf.annots;
using foxit.pdf.actions;
...
// Assuming PDFPage page has been loaded and parsed.
// Assuming the annnots in the page have been loaded.
// Create a new note annot and set the properties for it.
Annot annot = page.AddAnnot(Annot.Type.e_Note, new RectF(10, 350, 50, 400));
Note note = new Note(annot);
note.SetIconName("Comment");
note.SetSubject("Note");
note.SetTitle("Foxit SDK");
note.SetContent("Note annotation.");
note.SetCreationDateTime(GetLocalDateTime());
note.SetModifiedDateTime(GetLocalDateTime());
note.SetUniqueID(RandomUID());
// Add popup to note annotation.
Annot annot_popup = page.AddAnnot(Annot.Type.e_Popup, new RectF(300, 450, 500, 550));
Popup popup = new Popup(annot);
popup.SetBorderColor(0x00FF00);
popup.SetOpenStatus(false);
popup.SetModifiedDateTime(GetLocalDateTime());
note.SetPopup(popup);
// Appearance should be reset.
note.ResetAppearanceStream();
...
How to get a specific annotation in a PDF using device coordinates
using foxit; using foxit.common; using foxit.pdf; using foxit.pdf.graphics; using foxit.pdf.annots; ... // Assuming PDFDoc doc has been loaded. // Assuming PDFPage page has been loaded and parsed. ... int width = (int)page.GetWidth(); int height = (int)page.GetHeight(); Matrix2D matrix = page.GetDisplayMatrix(0, 0, width, height, page.GetRotation()); // Assuming PointF point has been got. float tolerance = 3.0f; Annot annot = page.GetAnnotAtDevicePoint(point, tolerance, matrix); ...
How to extract the texts under text markup annotations
using foxit.common;
using foxit.pdf;
using foxit.pdf.annots;
...
// Assuming PDFDoc doc has been loaded.
...
using (var page = doc.GetPage(0))
{
// Parse the first page.
page.StartParse((int) PDFPage.ParseFlags.e_ParsePageNormal, null, false);
// Get a TextPage object.
using (var text_page = new TextPage(page, (int) TextPage.TextParseFlags.e_ParseTextNormal))
{
int annot_count = page.GetAnnotCount();
for (int i = 0; i<annot_count; i++)
{
Annot annot = page.GetAnnot(i);
TextMarkup text_markup = new TextMarkup(annot);
if (!text_markup.IsEmpty())
{
// Get the texts which intersect with a text markup annotation.
string text = text_page.GetTextUnderAnnot(text_markup);
}
}
}
}
How to add richtext for freetext annotation
using foxit.common;
using foxit.pdf;
using foxit.pdf.annots;
// Make sure that SDK has already been initialized successfully.
// Load a PDF document, get a PDF page and parse it.
// Add a new freetext annotation, as text box.
FreeText freetext = null;
Annot annot = null;
using (annot = pdf_page.AddAnnot(Annot.Type.e_FreeText, new RectF(50, 50, 150, 100)))
using (freetext = new FreeText(annot))
{
// Set annotation's properties.
// Add/insert richtext string with style.
using (RichTextStyle richtext_style = new RichTextStyle())
{
{
String font_name = "Times New Roman";
using (richtext_style.font = new foxit.common.Font(font_name, 0, foxit.common.Font.Charset.e_CharsetANSI, 0))
{
richtext_style.text_color = 0xFF0000;
richtext_style.text_size = 10;
freetext.AddRichText("Textbox annotation ", richtext_style);
richtext_style.text_color = 0x00FF00;
richtext_style.is_underline = true;
freetext.AddRichText("1-underline ", richtext_style);
}
}
{
String font_name = "Calibri";
using (richtext_style.font = new foxit.common.Font(font_name, 0, foxit.common.Font.Charset.e_CharsetANSI, 0))
{
richtext_style.text_color = 0x0000FF;
richtext_style.is_underline = false;
richtext_style.is_strikethrough = true;
int richtext_count = freetext.GetRichTextCount();
freetext.InsertRichText(richtext_count - 1, "2_strikethrough ", richtext_style);
}
}
}
// Appearance should be reset.
freetext.resetAppearanceStream();
}
Import annotations from or export annotations to a FDF file
In Foxit PDF SDK, annotations can be created with data not only from applications but also from FDF files. At the same time, PDF SDK supports to export annotations to FDF files.
Example:
How to load annotations from a FDF file and add them into the first page of a given PDF
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; // Assuming PDFDoc doc has been loaded. ... string fdf_file = "The FDF file path"; foxit.fdf.FDFDoc fdf_doc = new foxit.fdf.FDFDoc(fdf_file); pdf_doc.ImportFromFDF(fdf_doc, (int)foxit.pdf.PDFDoc.DataType.e_Annots, new Range()); ...
Image Conversion
Foxit PDF SDK provides APIs for conversion between PDF files and images. Applications could easily fulfill functionalities like image creation and image conversion which supports the following image formats: BMP, TIFF, PNG, JPX, JPEG, and GIF. Foxit PDF SDK can make the conversion between PDF files and the supported image formats except for GIF. It only supports converting GIF images to PDF files.
Example:
How to convert PDF pages to bitmap files
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
// Assuming PDFDoc doc has been loaded.
...
Image image = new Image();
// Get page count
int nPageCount = doc.GetPageCount();
for(int i=0;i<nPageCount;i++)
{
using (PDFPage page = doc.GetPage(i))
{
// Parse page.
page.StartParse((int)foxit.pdf.PDFPage.ParseFlags.e_ParsePageNormal, null, false);
int width = (int)(page.GetWidth());
int height = (int)(page.GetHeight());
Matrix2D matrix = page.GetDisplayMatrix(0, 0, width, height, page.GetRotation());
// Prepare a bitmap for rendering.
foxit.common.Bitmap bitmap = new foxit.common.Bitmap(width, height, foxit.common.Bitmap.DIBFormat.e_DIBArgb, System.IntPtr.Zero, 0);
bitmap.FillRect(0xFFFFFFFF, null);
// Render page
Renderer render = new Renderer(bitmap, false);
render.StartRender(page, matrix, null);
image.AddFrame(bitmap);
}
}
...
Note: For pdf2image functionality, if the PDF file contains images larger than 1G, it is recommended to process the images using tiled rendering. Otherwise, it may occur exceptions. Following is a brief implementation of tiled rendering.
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
page.StartParse((int)foxit.pdf.PDFPage.ParseFlags.e_ParsePageNormal, null, false);
int width = (int)(page.GetWidth());
int height = (int)(page.GetHeight());
int render_sum = 10;
int width_scale = 1;
int height_scale = 1;
int little_width = width * width_scale;
int little_height = height / render_sum * height_scale;
for (int i = 0; i < render_sum; i++)
{
// According to Matrix, do module rendering for large PDF files.
Matrix2D matrix = page.GetDisplayMatrix(0, -1 * i * little_height, little_width, height * height_scale, page.GetRotation());
// Prepare a bitmap for rendering.
foxit.common.Bitmap bitmap = new foxit.common.Bitmap(width, height, foxit.common.Bitmap.DIBFormat.e_DIBArgb, System.IntPtr.Zero, 0);
bitmap.FillRect(0xFFFFFFFF,null);
Renderer render = new Renderer(bitmap, false);
render.StartRender(page, matrix, null);
// The bitmap data will be added to the end of image file after rendering.
...
matrix.DisPose();
draw.Dispose();
render.Dispose();
}
How to convert an image file to PDF file
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
// Assuming PDFDoc doc has been loaded.
...
Image image = new Image(input_file);
int count = image.GetFrameCount();
for (int i = 0; i < count; i++) {
PDFPage page = doc.InsertPage(i, PDFPage.Size.e_SizeLetter);
page.StartParse((int)PDFPage.ParseFlags.e_ParsePageNormal, null, false);
// Add image to page
page.AddImage(image, i, new PointF(0, 0), page.GetWidth(), page.GetHeight(), true);
}
doc.SaveAs(output_file, (int)PDFDoc.SaveFlags.e_SaveFlagNoOriginal);
...
Watermark
Watermark is a type of PDF annotation and is widely used in PDF document. Watermark is a visible embedded overlay on a document consisting of text, a logo, or a copyright notice. The purpose of a watermark is to identify the work and discourage its unauthorized use. Foxit PDF SDK provides APIs to work with watermark, allowing applications to create, insert, release and remove watermarks.
Example:
How to create a text watermark and insert it into the first page
using foxit.common; using foxit.pdf; ... // Assuming PDFDoc doc has been loaded. WatermarkSettings settings = new WatermarkSettings(); settings.offset_x = 0; settings.offset_y = 0; settings.opacity = 90; settings.position = Position.e_PosTopRight; settings.rotation = -45.0f; settings.scale_x = 1.0f; settings.scale_y = 1.0f; WatermarkTextProperties text_properties = new WatermarkTextProperties(); text_properties.alignment = Alignment.e_AlignmentCenter; text_properties.color = 0xF68C21; text_properties.font_style = WatermarkTextProperties.FontStyle.e_FontStyleNormal; text_properties.line_space = 1; text_properties.font_size = 12.0f; text_properties.font = font; Watermark watermark = new Watermark(doc, "Foxit PDF SDK\nwww.foxitsoftware.com", text_properties, settings); watermark.InsertToPage(doc.GetPage(0)); // Save document to file ...
How to create an image watermark and insert it into the first page
using foxit.common; using foxit.pdf; ... // Assuming PDFDoc doc has been loaded. // Assuming PDFPage page has been loaded and parsed. WatermarkSettings settings = new WatermarkSettings(); settings.flags = (int)(WatermarkSettings.Flags.e_FlagASPageContents | WatermarkSettings.Flags.e_FlagOnTop); settings.offset_x = 0.0f; settings.offset_y = 0.0f; settings.opacity = 20; settings.position = Position.e_PosCenter; settings.rotation = 0.0f; Image image = new Image(image_file); foxit.common.Bitmap bitmap = image.GetFrameBitmap(0); settings.scale_x = page.GetWidth() * 0.618f / bitmap.GetWidth(); settings.scale_y = settings.scale_x; Watermark watermark = new Watermark(doc, image, 0, settings); watermark.InsertToPage(doc.GetPage(0)); // Save document to file. ...
How to remove all watermarks from a page
using foxit.common; using foxit.pdf; ... // Assuming PDFPage page has been loaded and parsed. ... page.RemoveAllWatermarks(); ... // Save document to file ...
Barcode
A barcode is an optical machine-readable representation of data relating to the object to which it is attached. Originally barcodes systematically represented data by varying the widths and spacing of parallel lines, and may be referred to as linear or one-dimensional (1D). Later they evolved into rectangles, dots, hexagons and other geometric patterns in two dimensions (2D). Although 2D systems use a variety of symbols, they are generally referred to as barcodes as well. Barcodes originally were scanned by special optical scanners called barcode readers. Later, scanners and interpretive software became available on devices including desktop printers and smartphones. Foxit PDF SDK provides applications to generate a barcode bitmap from a given string. The barcode types that Foxit PDF SDK supports are listed in Table 3-2.
Table 3-2
| Barcode Type | Code39 | Code128 | EAN8 | UPCA | EAN13 | ITF | PDF417 | QR |
| Dimension | 1D | 1D | 1D | 1D | 1D | 1D | 2D | 2D |
Example:
How to generate a barcode bitmap from a string
using foxit; using foxit.common; using foxit.common.fxcrt; ... // Strings used as barcode content. String sz_code_str = "TEST-SHEET"; // Barcode format types. Barcode.Format sz_code_format = Barcode.Format.e_FormatCode39; //Format error correction level of QR code. Barcode.QRErrorCorrectionLevel qr_level = Barcode.QRErrorCorrectionLevel.e_QRCorrectionLevelLow; //Image names for the saved image files for QR code. String sz_bmp_qr_name = "/QR_CODE_TestForBarcodeQrCode_L.bmp"; // Unit width for barcode in pixels, preferred value is 1-5 pixels. int unit_width = 2; // Unit height for barcode in pixels, preferred value is >= 20 pixels. int unit_height = 120; Barcode barcode; Barcode barcode = new Barcode(); foxit.common.Bitmap bitmap = barcode.GenerateBitmap(sz_code_str, sz_code_format, unit_width, unit_height, qr_level); ...
Security
Foxit PDF SDK provides a range of encryption and decryption functions to meet different level of document security protection. Users can use regular password encryption and certificate-driven encryption, or using their own security handler for custom security implementation. It also provides APIs to integrate with the third-party security mechanism (Microsoft RMS). These APIs allow developers to work with the Microsoft RMS SDK to both encrypt (protect) and decrypt (unprotect) PDF documents.
Note: For more detailed information about the RMS encryption and decryption, please refer to the simple demo “security” in the “examples\simple_demo” folder of the download package.
Example:
How to encrypt a PDF file with user password “123” and owner password “456”
using foxit.common;
using foxit.pdf;
...
using (var handler = new StdSecurityHandler())
{
using (var encrypt_data = new StdEncryptData(true, -4, SecurityHandler.CipherType.e_CipherAES, 16))
{
handler.Initialize(encrypt_data, “123”, “456”);
doc.SetSecurityHandler(handler);
doc.SaveAs(output_file, (int)PDFDoc.SaveFlags.e_SaveFlagNormal);
}
}
...
How to encrypt a PDF file with Certificate
using foxit.common;
using foxit.pdf;
...
PDFDoc doc = new PDFDoc(input_file);
ErrorCode error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess){
return;
}
// Do encryption.
string cert_file_path = input_path + "foxit.cer";
var cms = new EnvelopedCms(new ContentInfo(seed));
cms.ContentEncryptionAlgorithm.Oid.Value = "1.2.840.113549.3.4";
cms.Encrypt(new CmsRecipient(new X509Certificate2(cert_file_path)));
byte[] bytes = cms.Encode();
byte[] data = new byte[20 + bytes.Length];
Array.Copy(seed, 0, data, 0, 20);
Array.Copy(bytes, 0, data, 20, bytes.Length);
SHA1 sha1 = new SHA1CryptoServiceProvider();
byte[] initial_key = new byte[16];
Array.Copy(sha1.ComputeHash(data), initial_key, initial_key.Length);
StringArray string_array = new StringArray();
string_array.AddBytes(bytes);
using (var handler = new CertificateSecurityHandler())
{
using (var encrypt_data = new CertificateEncryptData())
{
encrypt_data.Set(true, SecurityHandler.CipherType.e_CipherAES,string_array);
handler.Initialize(encrypt_data, initial_key);
doc.SetSecurityHandler(handler);
doc.SaveAs(output_file, (int)PDFDoc.SaveFlags.e_SaveFlagNormal);
}
}
...
How to encrypt a PDF file with Foxit DRM
using foxit.common;
using foxit.pdf;
...
PDFDoc doc = new PDFDoc(input_file);
ErrorCode error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess){
return;
}
// Do encryption.
var handler = new DRMSecurityHandler();
var encrypt_data = new DRMEncryptData(true,"Simple-DRM-filter", SecurityHandler.CipherType.e_CipherAES, 16, true, -4);
string file_id = "Simple-DRM-file-ID";
string initialize_key = "Simple-DRM-initialize-key";
handler.Initialize(encrypt_data, file_id, initialize_key);
doc.SetSecurityHandler(handler);
doc.SaveAs(output_file, (int)PDFDoc.SaveFlags.e_SaveFlagNormal);
...
Reflow
Reflow is a function that rearranges page content when the page size changes. It is useful for applications that have output devices with difference sizes. Reflow frees the applications from considering layout for different devices. This function provides APIs to create, render, release and access properties of ‘reflow’ pages.
Example:
How to create a reflow page and render it to a bmp file.
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; ... // Assuming PDFDoc doc has been loaded. PDFPage page = doc.GetPage(0); // Parse PDF page. page.StartParse((int)foxit.pdf.PDFPage.ParseFlags.e_ParsePageNormal, null, false); ReflowPage reflow_page = new ReflowPage(page); // Set some arguments used for parsing the reflow page. reflow_page.SetLineSpace(0); reflow_page.SetZoom(100); reflow_page.SetParseFlags((int)ReflowPage.Flags.e_WithImage); // Parse reflow page. reflow_page.StartParse(null); // Get actual size of content of reflow page. The content size does not contain the margin. float content_width = reflow_page.GetContentWidth(); float content_height = reflow_page.GetContentHeight(); // Assuming Bitmap bitmap has been created. // Render reflow page. Renderer renderer = new Renderer(bitmap, false); Matrix2D matrix = reflow_page.GetDisplayMatrix(0, 0); renderer.StartRenderReflowPage(reflow_page, matrix, null); ...
Asynchronous PDF
Asynchronous PDF technique is a way to access PDF pages without loading the whole document when it takes a long time. It’s especially designed for accessing PDF files on internet. With asynchronous PDF technique, applications do not have to wait for the whole PDF file to be downloaded before accessing it. Applications can open any page when the data of that page is available. It provides a convenient and efficient way for web reading applications. For how to open and parse pages with asynchronous mode, you can refer to the simple demo “async_load” in the “examples\simple_demo” folder of the download package.
Pressure Sensitive Ink
Pressure Sensitive Ink (PSI) is a technique to obtain varying electrical outputs in response to varying pressure or force applied across a layer of pressure sensitive devices. In PDF, PSI is usually used for hand writing signatures. PSI data are collected by touching screens or handwriting on boards. PSI data contains coordinates and canvas of the operating area which can be used to generate appearance of PSI. Foxit PDF SDK allows applications to create PSI, access properties, operate on ink and canvas, and release PSI.
Example:
How to create a PSI and set the related properties for it
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; using foxit.pdf.annots; ... PSI psi = new PSI(480, 180, true); // Set ink diameter. psi.SetDiameter(9); // Set ink color. psi.SetColor(0x434236); // Set ink opacity. psi.SetOpacity(0.8f); // Add points to pressure sensitive ink. float x = 121.3043f; float y = 326.6846f; float pressure = 0.0966f; Path.PointType type = Path.PointType.e_TypeMoveTo; foxit.common.fxcrt.PointF pt = new foxit.common.fxcrt.PointF(x, y); psi.AddPoint(pt, type, pressure); ...
Wrapper
Wrapper provides a way for users to save their own data related to a PDF document. For example, when opening an encrypted unauthorized PDF document, users may get an error message. In this case, users can still access wrapper data even when they do not have permissions to the PDF content. The wrapper data could be used to provide information like where to get decryption method of this document.
Example:
How to open a document including wrapper data
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.graphics;
using foxit.pdf.objects;
// Assuming PDFDoc doc has been loaded.
// file_name is PDF document which includes wrapper data.
PDFDoc doc = new PDFDoc(file_name);
ErrorCode code = doc.Load(null);
if (code != ErrorCode.e_ErrSuccess)
{
return;
}
if (!doc.IsWrapper())
{
return;
}
long offset = doc.GetWrapperOffset();
FileReader file_reader = new FileReader(offset);
file_reader.LoadFile(file_name);
...
PDF Objects
There are eight types of objects in PDF: Boolean object, numerical object, string object, name object, array object, dictionary object, stream object and null object. PDF objects are document level objects that are different from page objects (see 3.24) which are associated with a specific page each. Foxit PDF SDK provides APIs to create, modify, retrieve and delete these objects in a document.
Example:
How to remove some properties from catalog dictionary
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.graphics;
using foxit.pdf.objects;
...
// Assuming PDFDoc doc has been loaded.
PDFDictionary doc_catalog_dict = doc.GetCatalog();
String[] key_strings = { "Type", "Boolean", "Name", "String", "Array", "Dict" };
int count = key_strings.Length;
for (int i = 0; i < count; i++)
{
if (catalog.HasKey(key_strings[i]))
{
catalog.RemoveAt(key_strings[i]);
}
}
...
Page Object
Page object is a feature that allows novice users having limited knowledge of PDF objects (see 3.23 for details of PDF objects) to be able to work with text, path, image, and canvas objects. Foxit PDF SDK provides APIs to add and delete PDF objects in a page and set specific attributes. Using page object, users can create PDF page from object contents. Other possible usages of page object include adding headers and footers to PDF documents, adding an image logo to each page, or generating a template PDF on demand.
Example:
How to create a text object in a PDF page
using foxit.common;
using foxit.pdf;
using foxit.pdf.graphics;
using foxit.common.fxcrt;
...
// Assuming PDFPage page has been loaded and parsed.
long position = page.GetLastGraphicsObjectPosition(GraphicsObject.Type.e_TypeText);
TextObject text_object = TextObject.Create();
text_object.SetFillColor(0xFFFF7F00);
// Prepare text state.
TextState state = new TextState();
Font font = new Font("Simsun", (int)Font.Styles.e_StylesSmallCap, Font.Charset.e_CharsetGB2312, 0);
state.font_size = 80.0f;
state.font = font;
state.textmode = TextState.Mode.e_ModeFill;
text_object.SetTextState(page, state, false, 750);
// Set text.
text_object.SetText("Foxit Software");
long last_position = page.InsertGraphicsObject(position, text_object);
...
How to add an image logo to a PDF page
using foxit.common; using foxit.pdf; using foxit.pdf.graphics; using foxit.common.fxcrt; ... // Assuming PDFPage page has been loaded and parsed. long position = page.GetLastGraphicsObjectPosition(GraphicsObject.Type.e_TypeImage); Image image = new Image(image_file); ImageObject image_object = ImageObject.Create(page.GetDocument()); image_object.SetImage(image, 0); float width = image.GetWidth(); float height = image.GetHeight(); float page_width = page.GetWidth(); float page_height = page.GetHeight(); image_object.SetMatrix(new Matrix2D(width, 0, 0, height, (page_width - width) / 2.0f, (page_height - height) / 2.0f)); page.InsertGraphicsObject(position, image_object); page.GenerateContent(); ...
Marked content
In PDF document, a portion of content can be marked as marked content element. Marked content helps to organize the logical structure information in a PDF document and enables stylized tagged PDF. Tagged PDF has a standard structure types and attributes that allow page content to be extracted and reused for other purposes. More details about marked content could be found in chapter 10.5 of PDF reference 1.7 [1].
Example:
How to get marked content in a page and get the tag name
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.graphics;
using foxit.pdf.objects;
...
// Assuming PDFPage page has been loaded and parsed.
long position = page.GetFirstGraphicsObjectPosition(GraphicsObject.Type.e_TypeText);
GraphicsObject text_obj = page.GetGraphicsObject(position);
MarkedContent content = text_obj.GetMarkedContent();
int nCount = content.GetItemCount();
// Get marked content property
for (int i = 0; i < nCount; i++)
{
String tag_name = content.GetItemTagName(i);
int mcid = content.GetItemMCID(i);
}
...
Layer
PDF Layers, in other words, Optional Content Groups (OCG), are supported in Foxit PDF SDK. Users can selectively view or hide the contents in different layers of a multi-layer PDF document. Multi-layers are widely used in many application domains such as CAD drawings, maps, layered artwork and multi-language document, etc.
In Foxit PDF SDK, a PDF layer is associated with a layer node. To retrieve a layer node, user should construct a PDF LayerTree object first and then call function LayerTree.GetRootNode to get the root layer node of the whole layer tree. Furthermore, you can enumerate all the nodes in the layer tree from the root layer node. Foxit PDF SDK provides APIs to get/set layer data, view or hide the contents in different layers, set layers’ name, add or remove layers, and edit layers.
Example:
How to create a PDF layer
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; ... // Assuming PDFDoc doc has been loaded. LayerTree layertree = new LayerTree(doc); LayerNode root = layertree.GetRootNode(); ...
How to set all the layer nodes information
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
...
// Assuming PDFDoc doc has been loaded.
public static void SetAllLayerNodesInformation(LayerNode layer_node)
{
if (layer_node.HasLayer())
{
layer_node.SetDefaultVisible(true);
layer_node.SetExportUsage(LayerTree.UsageState.e_StateUndefined);
layer_node.SetViewUsage(LayerTree.UsageState.e_StateOFF);
LayerPrintData print_data = new LayerPrintData("subtype_print", LayerTree.UsageState.e_StateON);
layer_node.SetPrintUsage (print_data);
LayerZoomData zoom_data = new LayerZoomData(1, 10);
layer_node.SetZoomUsage(zoom_data);
string new_name = "[View_OFF_Print_ON_Export_Undefined]" + layer_node.GetName();
layer_node.SetName(new_name);
}
int count = layer_node.GetChildrenCount();
for (int i = 0; i < count; i++)
{
using (LayerNode child = layer_node.GetChild(i))
{
SetAllLayerNodesInformation(child);
}
}
}
LayerTree layertree = new LayerTree(doc);
LayerNode root = layertree.GetRootNode();
if (root.IsEmpty())
{
return;
}
SetAllLayerNodesInformation(root);
...
How to edit layer tree
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; ... // Assuming PDFDoc doc has been loaded. LayerTree layertree = new LayerTree(doc); LayerNode root = layertree.GetRootNode(); int children_count = root.GetChildrenCount(); root.RemoveChild(children_count - 1); LayerNode child = root.GetChild(children_count - 2); LayerNode child0 = root.GetChild(0); child.MoveTo(child0, 0); child.AddChild(0, "AddedLayerNode", true); child.AddChild(0, "AddedNode", false);
Signature
PDF Signature module can be used to create and sign digital signatures for PDF documents, which protects the security of documents’ contents and avoids it to be tampered maliciously. It can let the receiver make sure that the document is released by the signer and the contents of the document are complete and unchanged. Foxit PDF SDK provides APIs to create digital signature, verify the validity of signature, delete existing digital signature, get and set properties of digital signature, display signature and customize the appearance of the signature form fields.
Note: Foxit PDF SDK provides default Signature handler which supports the following two types of signature filter and subfilter:
(1) filter: Adobe.PPKLite subfilter: adbe.pkcs7.detached
(2) filter: Adobe.PPKLite subfilter: adbe.pkcs7.sha1
If you use one of the above signature filter and subfilter, you can sign a PDF document and verify the validity of signature by default without needing to register a custom callback.
Example:
How to sign the PDF document with a signature
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using foxit.common;
using foxit.pdf;
using foxit;
using foxit.pdf.annots;
using foxit.common.fxcrt;
using System.Runtime.InteropServices;
using foxit.pdf.interform;
static foxit.common.DateTime GetLocalDateTime()
{
System.DateTimeOffset rime = System.DateTimeOffset.Now;
foxit.common.DateTime datetime = new foxit.common.DateTime();
datetime.year = (UInt16)rime.Year;
datetime.month = (UInt16)rime.Month;
datetime.day = (ushort)rime.Day;
datetime.hour = (UInt16)rime.Hour;
datetime.minute = (UInt16)rime.Minute;
datetime.second = (UInt16)rime.Second;
datetime.utc_hour_offset = (short)rime.Offset.Hours;
datetime.utc_minute_offset = (ushort)rime.Offset.Minutes;
return datetime;
}
static Signature AddSiganture(PDFPage pdf_page, string sub_filter) {
float page_height = pdf_page.GetHeight();
float page_width = pdf_page.GetWidth();
RectF new_sig_rect = new RectF(0, (float)(page_height*0.9), (float)(page_width*0.4), page_height);
// Add a new signature to page.
Signature new_sig = pdf_page.AddSignature(new_sig_rect);
if (new_sig.IsEmpty()) return null;
// Set values for the new signature.
new_sig.SetKeyValue(Signature.KeyName.e_KeyNameSigner, "Foxit PDF SDK");
String new_value = String.Format("As a sample for subfilter \"{0}\"", sub_filter);
new_sig.SetKeyValue(Signature.KeyName.e_KeyNameReason, new_value);
new_sig.SetKeyValue(Signature.KeyName.e_KeyNameContactInfo, "[email protected]");
new_sig.SetKeyValue(Signature.KeyName.e_KeyNameDN, "CN=CN,[email protected]");
new_sig.SetKeyValue(Signature.KeyName.e_KeyNameLocation, "Fuzhou, China");
new_value = String.Format("As a sample for subfilter \"{0}\"", sub_filter);
new_sig.SetKeyValue(Signature.KeyName.e_KeyNameText, new_value);
foxit.common.DateTime sign_time = GetLocalDateTime();
new_sig.SetSignTime(sign_time);
String image_file_path = input_path + "FoxitLogo.jpg";
using (Image image = new Image(image_file_path))
{
new_sig.SetImage(image, 0);
// Set appearance flags to decide which content would be used in appearance.
int ap_flags = Convert.ToInt32(Signature.APFlags.e_APFlagLabel | Signature.APFlags.e_APFlagSigner |
Signature.APFlags.e_APFlagReason | Signature.APFlags.e_APFlagDN |
Signature.APFlags.e_APFlagLocation | Signature.APFlags.e_APFlagText |
Signature.APFlags.e_APFlagSigningTime | Signature.APFlags.e_APFlagBitmap);
new_sig.SetAppearanceFlags(ap_flags);
}
return new_sig;
}
static void AdobePPKLiteSignature(PDFDoc pdf_doc) {
string filter = "Adobe.PPKLite";
string sub_filter = "adbe.pkcs7.detached";
using (PDFPage pdf_page = pdf_doc.GetPage(0))
{
// Add a new signature to first page.
using (Signature new_signature = AddSiganture(pdf_page, sub_filter))
{
// Set filter and subfilter for the new signature.
new_signature.SetFilter(filter);
new_signature.SetSubFilter(sub_filter);
// Sign the new signature.
String signed_pdf_path = output_directory + "signed_newsignature.pdf";
String cert_file_path = input_path + "foxit_all.pfx";
byte[] cert_file_password = Encoding.ASCII.GetBytes("123456");
new_signature.StartSign(cert_file_path, cert_file_password,
Signature.DigestAlgorithm.e_DigestSHA1, signed_pdf_path, IntPtr.Zero, null);
Console.WriteLine("[Sign] Finished!");
}
}
}
static void Main(String[] args)
{
...
AdobePPKLiteSignature(pdf_doc);
...
}
LTV
From version 7.0, Foxit PDF SDK provides APIs to establish long term validation (LTV) of signatures, which is mainly used to solve the verification problem of signatures that have already expired. LTV requires DSS (Document Security Store) which contains the verification information of the signatures, as well as DTS (Document Timestamp Signature) which belongs to the type of time stamp signature.
In order to support LTV, Foxit PDF SDK provides:
Support for adding the signatures of time stamp type, and provides a default signature callback for the subfilter “ETSI.RFC3161”.
TimeStampServerMgr and TimeStampServer classes, which are used to set and manager the server for time stamp. The default signature callback for the subfilter “ETSI.RFC3161” will use the default time stamp server.
LTVVerifier class which offers the functionalities of verifying signatures and adding DSS information to documents. It also provides a basic default RevocationCallback which is required by LTVVerifier.
Following lists an example about how to establish long term validation of signatures using the default signature callback for subfilter “ETSI.RFC3161” and the default RevocationCallback. For more details, please refer to the simple demo “ltv” in the “examples\simple_demo” folder of the download package.
Example:
How to establish long term validation of signatures using the default signature callback for subfilter “ETSI.RFC3161” and the default RevocationCallback
using System;
using foxit.common;
using foxit.pdf;
using foxit;
using foxit.common.fxcrt;
// Initialize time stamp server manager, add and set a default time stamp server, which will be used by default signature callback for time stamp signature.
TimeStampServerMgr.Initialize();
using (TimeStampServer timestamp_server = TimeStampServerMgr.AddServer(server_name, server_url, server_username, server_password))
{
TimeStampServerMgr.SetDefaultServer(timestamp_server);
// Assume that "signed_pdf_path" represents a signed PDF document which contains signed signature.
using (PDFDoc pdf_doc = new PDFDoc(signed_pdf_path))
{
pdf_doc.StartLoad(null, true, null);
// Use LTVVerifier to verify and add DSS.
using (LTVVerifier ltv_verifier = new LTVVerifier(pdf_doc, true, true, false, LTVVerifier.TimeType.e_SignatureCreationTime))
{
// Set verifying mode which is necessary.
ltv_verifier.SetVerifyMode(LTVVerifier.VerifyMode.e_VerifyModeAcrobat);
SignatureVerifyResultArray sig_verify_result_array = ltv_verifier.Verify();
for (uint i = 0; i < sig_verify_result_array.GetSize(); i++)
{
// ltv state would be e_LTVStateNotEnable here.
SignatureVerifyResult.LTVState ltv_state = sig_verify_result_array.GetAt(i).GetLTVState();
if ((sig_verify_result_array.GetAt(i).GetSignatureState() & Convert.ToUInt32(Signature.States.e_StateVerifyValid)) > 0)
ltv_verifier.AddDSS(sig_verify_result_array.GetAt(i));
}
// Add a time stamp signature as DTS and sign it. "saved_ltv_pdf_path" represents the newly saved signed PDF file.
using (PDFPage pdf_page = pdf_doc.GetPage(0))
{
// The new time stamp signature will have default filter name "Adobe.PPKLite" and default subfilter name "ETSI.RFC3161".
Signature timestamp_signature = pdf_page.AddSignature(new RectF(), "", Signature.SignatureType.e_SignatureTypeTimeStamp, true);
byte[] empty_byte = Encoding.ASCII.GetBytes("");
Progressive sign_progressive = timestamp_signature.StartSign("", empty_byte, Signature.DigestAlgorithm.e_DigestSHA256,
saved_ltv_pdf_path, IntPtr.Zero, null);
if (sign_progressive.GetRateOfProgress() != 100)
sign_progressive.Continue();
// Then use LTVVeirfier to verify the new signed PDF file.
using (PDFDoc check_pdf_doc = new PDFDoc(saved_ltv_pdf_path))
{
check_pdf_doc.StartLoad(null, true, null);
// Use LTVVeirfier to verify.
using (LTVVerifier ltv_verifier = new LTVVerifier(pdf_doc, true, true, false, LTVVerifier.TimeType.e_SignatureCreationTime))
{
// Set verifying mode which is necessary.
ltv_verifier.SetVerifyMode(LTVVerifier.VerifyMode.e_VerifyModeAcrobat);
SignatureVerifyResultArray sig_verify_result_array = ltv_verifier.Verify();
for (uint i = 0; i < sig_verify_result_array.GetSize(); i++)
{
// ltv state would be e_LTVStateEnable here.
SignatureVerifyResult.LTVState ltv_state = sig_verify_result_array.GetAt(i).GetLTVState();
... // User can get other information from SignatureVerifyResult.
}
}
}
}
}
}
}
// Release time stamp server manager when everything is done.
TimeStampServerMgr.Release();
PAdES
From version 7.0, Foxit PDF SDK also supports PAdES (PDF Advanced Electronic Signature) which is the application for CAdES signature in the field of PDF. CAdES is a new standard for advanced digital signature, its default subfilter is “ETSI.CAdES.detached”. PAdES signature includes four levels: B-B, B-T, B-LT, and B-LTA.
B-B: Must include the basic attributes.
B-T: Must include document time stamp or signature time stamp to provide trusted time for existing signatures, based on B-B.
B-LT: Must include DSS/VRI to provide certificates and revocation information, based on B-T.
B-LTA: Must include the trusted time DTS for existing revocation information, based on B-LT.
Foxit PDF SDK provides a default signature callback for the subfilter “ETSI.CAdES.detached” to sign and verify the signatures (with subfilter “ETSI.CAdES.detached”). It also provides TimeStampServerMgr and TimeStampServer classes to set and manager the server for time stamp. The default signature callback for the subfilter “ETSI.CAdES.detached” will use the default time stamp server.
Foxit PDF SDK provides functions to get the level of PAdES from signature, and application level can also judge and determine the level of PAdES according to the requirements of each level.
PDF Action
PDF Action is represented as the base PDF action class. Foxit PDF SDK provides APIs to create a series of actions and get the action handlers, such as embedded goto action, JavaScript action, named action and launch action, etc.
Example:
How to create a URI action and insert to a link annot
using foxit.common;
using foxit.pdf;
using foxit;
using foxit.pdf.annots;
using foxit.common.fxcrt;
using foxit.pdf.annots;
using foxit.pdf.actions;
// Add link annotation
Link link = null;
Annot annot = null;
using (annot = page.AddAnnot(Annot.Type.e_Link, new RectF(350, 350, 380, 400)))
using (link = new Link(annot))
using (PDFDoc doc = page.GetDocument())
{
foxit.pdf.actions.Action action = null;
link.SetHighlightingMode(Annot.HighlightingMode.e_HighlightingToggle);
// Add action for link annotation
URIAction uriaction = null;
using (action = foxit.pdf.actions.Action.Create(doc, foxit.pdf.actions.Action.Type.e_TypeGoto))
using (uriaction = new URIAction(action))
{
uriaction.SetTrackPositionFlag(true);
uriaction.SetURI("www.foxitsoftware.com");
link.SetAction(uriaction);
// Appearance should be reset.
link.ResetAppearanceStream();
}
}
How to create a GoTo action and insert to a link annot
using foxit.common;
using foxit.pdf;
using foxit;
using foxit.pdf.annots;
using foxit.common.fxcrt;
using foxit.pdf.annots;
using foxit.pdf.actions;
using foxit.common;
using foxit.pdf;
using foxit;
using foxit.pdf.annots;
using foxit.common.fxcrt;
using foxit.pdf.annots;
using foxit.pdf.actions;
Link link = null;
Annot annot = null;
using (annot = page.AddAnnot(Annot.Type.e_Link, new RectF(350, 350, 380, 400)))
using (link = new Link(annot))
using (PDFDoc doc = page.GetDocument())
{
foxit.pdf.actions.Action action = null;
link.SetHighlightingMode(Annot.HighlightingMode.e_HighlightingToggle);
// Add action for link annotation
GotoAction gotoaction = null;
using (action = foxit.pdf.actions.Action.Create(doc, foxit.pdf.actions.Action.Type.e_TypeGoto))
using (gotoaction = new GotoAction(action))
{
Destination dest = Destination.CreateXYZ(doc, 0, 0, 0, 0);
gotoaction.SetDestination(dest);
link.SetAction(gotoaction);
// Appearance should be reset.
link.ResetAppearanceStream();
}
}
JavaScript
JavaScript was created to offload Web page processing from a server onto a client in Web-based applications. Foxit PDF SDK JavaScript implements extensions, in the form of new objects and their accompanying methods and properties, to the JavaScript language. It enables a developer to manage document security, communicate with a database, handle file attachments, and manipulate a PDF file so that it behaves as an interactive, web-enabled form, and so on.
JavaScript action is an action that causes a script to be compiled and executed by the JavaScript interpreter. Class foxit.pdf.actions.JavaScriptActionis derived from Action and offers functions to get/set JavaScript action data.
The JavaScript methods and properties supported by Foxit PDF SDK are listed in the appendix.
Example:
How to add JavaScript Action to Document
using foxit.pdf.annots;
using foxit.pdf.actions;
// Load Document doc.
...
using (foxit.pdf.actions.Action action = foxit.pdf.actions.Action.Create(doc, foxit.pdf.actions.Action.Type.e_TypeJavaScript))
using (JavaScriptAction javascipt_action = new JavaScriptAction(action))
{
javascipt_action.SetScript("app.alert(\"Hello Foxit \");");
using (AdditionalAction aa = new AdditionalAction(doc))
{
aa.SetAction(AdditionalAction.TriggerEvent.e_TriggerDocWillClose, javascipt_action);
aa.DoJSAction(AdditionalAction.TriggerEvent.e_TriggerDocWillClose);
}
}
...
How to add JavaScript Action to Annotation
using foxit.pdf.annots;
using foxit.pdf.actions;
...
// Load Document and get a widget annotation.
...
using (foxit.pdf.actions.Action action = foxit.pdf.actions.Action.Create(page.GetDocument(), foxit.pdf.actions.Action.Type.e_TypeJavaScript))
using (JavaScriptAction javascipt_action = new JavaScriptAction(action))
{
javascipt_action.SetScript("app.alert(\"Hello Foxit \");");
using (AdditionalAction aa = new AdditionalAction(annot))
{
aa.SetAction(AdditionalAction.TriggerEvent.e_TriggerAnnotMouseButtonPressed, javascipt_action);
aa.DoJSAction(AdditionalAction.TriggerEvent.e_TriggerAnnotMouseButtonPressed);
}
}
...
How to add JavaScript Action to FormField
using foxit.pdf.interform;
using foxit.pdf.actions;
...
// Load Document and get a form field.
...
// Add text field.
using (Control control = form.AddControl(page, "Text Field0", Field.Type.e_TypeTextField, new RectF(50f, 600f, 90f, 640f)))
using (Control control1 = form.AddControl(page, "Text Field1", Field.Type.e_TypeTextField, new RectF(100f, 600f, 140f, 640f)))
using (Control control2 = form.AddControl(page, "Text Field2", Field.Type.e_TypeTextField, new RectF(150f, 600f, 190f, 640f)))
using (Field field = control.GetField())
{
field.SetValue("3");
// Update text field's appearance.
using (Widget widget = control.GetWidget())
widget.ResetAppearanceStream();
using (Field field1 = control1.GetField())
{
field1.SetValue("23");
// Update text field's appearance.
using(Widget widget1 = control1.GetWidget())
widget1.ResetAppearanceStream();
using (Field field2 = control2.GetField())
using (PDFDoc doc = form.GetDocument())
using (foxit.pdf.actions.Action action = foxit.pdf.actions.Action.Create(form.GetDocument(), foxit.pdf.actions.Action.Type.e_TypeJavaScript))
using (foxit.pdf.actions.JavaScriptAction javascipt_action = new foxit.pdf.actions.JavaScriptAction(action))
{
javascipt_action.SetScript("AFSimple_Calculate(\"SUM\", new Array (\"Text Field0\", \"Text Field1\"));");
using (AdditionalAction aa = new AdditionalAction(field2))
{
aa.SetAction(AdditionalAction.TriggerEvent.e_TriggerFieldRecalculateValue, javascipt_action);
// Update text field's appearance.
using(Widget widget2 = control2.GetWidget())
widget2.ResetAppearanceStream();
}
}
}
}
...
How to add a new annotation to PDF using JavaScript
using foxit.pdf.annots;
using foxit.pdf.actions;
...
// Load Document and get form field, construct a Form object and a Filler object.
...
using (foxit.pdf.actions.Action action = foxit.pdf.actions.Action.Create(form.GetDocument(), foxit.pdf.actions.Action.Type.e_TypeJavaScript))
using (foxit.pdf.actions.JavaScriptAction javascipt_action = new foxit.pdf.actions.JavaScriptAction(action))
{
javascipt_action.SetScript("var annot = this.addAnnot({ page : 0, type : \"Square\", rect : [ 0, 0, 100, 100 ], name : \"UniqueID\", author : \"A. C. Robat\", contents : \"This section needs revision.\" });");
using (AdditionalAction aa = new AdditionalAction(field))
{
aa.SetAction(AdditionalAction.TriggerEvent.e_TriggerAnnotCursorEnter, javascipt_action);
aa.DoJSAction(AdditionalAction.TriggerEvent.e_TriggerAnnotCursorEnter);
}
}
...
How to get/set properties of annotations (strokeColor, fillColor, readOnly, rect, type) using JavaScript
using foxit.pdf.annots;
using foxit.pdf.actions;
...
// Load Document and get form field, construct a Form object and a Filler object.
...
using (foxit.pdf.actions.Action action = foxit.pdf.actions.Action.Create(form.GetDocument(), foxit.pdf.actions.Action.Type.e_TypeJavaScript))
// Get properties of annotations.
using (foxit.pdf.actions.JavaScriptAction javascipt_action = new foxit.pdf.actions.JavaScriptAction(action))
{
javascipt_action.SetScript("var ann = this.getAnnot(0, \" UniqueID \"); if (ann != null) { console.println(\"Found it! type: \" + ann.type); console.println(\"readOnly: \" + ann.readOnly); console.println(\"strokeColor: \" + ann.strokeColor);console.println(\"fillColor: \" + ann.fillColor); console.println(\"rect: \" + ann.rect);}");
using (AdditionalAction aa = new AdditionalAction(field))
{
aa.SetAction(AdditionalAction.TriggerEvent.e_TriggerAnnotCursorEnter, javascipt_action);
aa.DoJSAction(AdditionalAction.TriggerEvent.e_TriggerAnnotCursorEnter);
}
}
// Set properties of annotations (only take strokeColor as an example).
using (foxit.pdf.actions.JavaScriptAction javascipt_action1 = new foxit.pdf.actions.JavaScriptAction(action))
{
javascipt_action1.SetScript("var ann = this.getAnnot(0, \"UniqueID\");if (ann != null) { ann.strokeColor = color.blue; }");
using (AdditionalAction aa1 = new AdditionalAction(field1))
{
aa1.SetAction(AdditionalAction.TriggerEvent.e_TriggerAnnotCursorEnter, javascipt_action1);
aa1.DoJSAction(AdditionalAction.TriggerEvent.e_TriggerAnnotCursorEnter);
}
}
...
How to destroy annotation using JavaScript
using foxit.pdf.annots;
using foxit.pdf.actions;
...
// Load Document and get form field, construct a Form object and a Filler object.
...
using (foxit.pdf.actions.Action action = foxit.pdf.actions.Action.Create(form.GetDocument(), foxit.pdf.actions.Action.Type.e_TypeJavaScript))
using (foxit.pdf.actions.JavaScriptAction javascipt_action = new foxit.pdf.actions.JavaScriptAction(action))
{
javascipt_action.SetScript("var ann = this.getAnnot(0, \" UniqueID \"); if (ann != null) { ann.destroy(); } ");
using (AdditionalAction aa = new AdditionalAction(field))
{
aa.SetAction(AdditionalAction.TriggerEvent.e_TriggerAnnotCursorEnter, javascipt_action);
aa.DoJSAction(AdditionalAction.TriggerEvent.e_TriggerAnnotCursorEnter);
}
}
...
Redaction
Redaction is the process of removing sensitive information while keeping the document’s layout. It allows users to permanently remove (redact) visible text and images from PDF documents to protect confidential information, such as social security numbers, credit card information, product release dates, and so on.
Redaction is a type of markup annotation, which is used to mark some contents of a PDF file and then the contents will be removed once the redact annotations are applied.
To do Redaction, you can use the following APIs:
Call function foxit.addon.Redaction.Redaction to create a redaction module. If module “Redaction” is not defined in the license information which is used in function common.Library.Initialize, it means user has no right in using redaction related functions and this constructor will throw exception foxit.common.ErrorCode.e_ErrInvalidLicense .
Then call function foxit.addon.Redaction.MarkRedactAnnot to create a redaction object and mark page contents (text object, image object, and path object) which are to be redacted.
Finally call function foxit.addon.Redaction.Apply to apply redaction in marked areas: remove the text or graphics under marked areas permanently.
Note: To use the redaction feature, please make sure the license key has the permission of the ‘Redaction’ module.
Example:
How to redact the text “PDF” on the first page of a PDF
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.addon;
using foxit.pdf.annots;
...
using (Redaction redaction = new Redaction(doc))
{
using (PDFPage page = doc.GetPage(0))
{
// Parse PDF page.
page.StartParse((int)foxit.pdf.PDFPage.ParseFlags.e_ParsePageNormal, null, false);
TextPage text_page = new TextPage(page, (int)foxit.pdf.TextPage.TextParseFlags.e_ParseTextNormal);
TextSearch text_search = new TextSearch(text_page);
text_search.SetPattern("PDF");
RectFArray rect_array = new RectFArray();
while (text_search.FindNext())
{
RectFArray itemArray = text_search.GetMatchRects();
rect_array.InsertAt(rect_array.GetSize(), itemArray);
}
if (rect_array.GetSize() > 0)
{
Redact redact = redaction.MarkRedactAnnot(page, rect_array);
redact.ResetAppearanceStream();
doc.SaveAs(output_path + "AboutFoxit_redected_default.pdf", (int)foxit.pdf.PDFDoc.SaveFlags.e_SaveFlagNormal);
// set border color to Green
redact.SetBorderColor(0x00FF00);
// set fill color to Blue
redact.SetFillColor(0x0000FF);
// set rollover fill color to Red
redact.SetApplyFillColor(0xFF0000);
redact.ResetAppearanceStream();
doc.SaveAs(output_path + "AboutFoxit_redected_setColor.pdf", (int)foxit.pdf.PDFDoc.SaveFlags.e_SaveFlagNormal);
redact.SetOpacity((float)0.5);
redact.ResetAppearanceStream();
doc.SaveAs(output_path + "AboutFoxit_redected_setOpacity.pdf", (int)foxit.pdf.PDFDoc.SaveFlags.e_SaveFlagNormal);
if (redaction.Apply())
Console.WriteLine("Redact page(0) succeed.");
else
Console.WriteLine("Redact page(0) failed.");
redact.Dispose();
}
}
}
Comparison
Comparison feature lets you see the differences in two versions of a PDF. Foxit PDF SDK provides APIs to compare two PDF documents page by page, the differences between the two documents will be returned.
The differences can be defined into three types: delete, insert and replace. You can save these differences into a PDF file and mark them as annotations.
Note: To use the comparison feature, please make sure the license key has the permission of the ‘Comparison’ module.
Example:
How to compare two PDF documents and save the differences between them into a PDF file
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.pdf.annots;
using foxit.addon;
...
using (PDFDoc base_doc = new PDFDoc("input_base_file"))
{
error_code = base_doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess)
{
Library.Release();
return;
}
using (PDFDoc compared_doc = new PDFDoc("input_compared_file"))
{
error_code = compared_doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess)
{
Library.Release();
return;
}
using (Comparison comparison = new Comparison(base_doc, compared_doc))
{
// Start comparing.
CompareResults result = comparison.DoCompare(0, 0, (int)Comparison.CompareType.e_CompareTypeText);
CompareResultInfoArray oldInfo = result.results_base_doc;
CompareResultInfoArray newInfo = result.results_compared_doc;
uint oldInfoSize = oldInfo.GetSize();
uint newInfoSize = newInfo.GetSize();
using (PDFPage page = compared_doc.GetPage(0))
{
for (uint i = 0; i < newInfoSize; i++)
{
CompareResultInfo item = newInfo.GetAt(i);
CompareResultInfo.CompareResultType type = item.type;
if (type == CompareResultInfo.CompareResultType.e_CompareResultTypeDeleteText)
{
String res_string = String.Format("\"{0}\"", item.diff_contents);
CreateDeleteTextStamp(page, item.rect_array, 0xff0000, res_string, "Compare : Delete", "Text");
}
else if (type == CompareResultInfo.CompareResultType.e_CompareResultTypeInsertText)
{
String res_string = String.Format("\"{0}\"", item.diff_contents);
CreateDeleteText(page, item.rect_array, 0x0000ff, res_string, "Compare : Insert", "Text");
}
else if (type == CompareResultInfo.CompareResultType.e_CompareResultTypeReplaceText)
{
String res_string = String.Format("[Old]: \"{0}\"\r\n[New]: \"{1}\"", oldInfo.GetAt(i).diff_contents, item.diff_contents);
CreateSquigglyRect(page, item.rect_array, 0xe7651a, res_string, "Compare : Replace", "Text");
}
}
}
// Save the comparison result to a PDF file.
compared_doc.SaveAs(output_path + "result.pdf", (int)PDFDoc.SaveFlags.e_SaveFlagNormal);
}
}
}
Note: for CreateDeleteTextStamp, CreateDeleteText and CreateSquigglyRect functions, please refer to the simple demo “pdfcompare” located in the “examples\simple_demo” folder of the download package.
OCR
Optical Character Recognition, or OCR, is a software process that enables images or printed text
to be translated into machine-readable text. OCR is most commonly used when scanning paper
documents to create electronic copies, but can also be performed on existing electronic
documents (e.g. PDF).
From version 9.0, Linux x64 platform supports OCR feature, and the OCR engine has been upgraded, please contact Foxit support team or sales team to get the latest engine files package.
This section will provide instructions on how to set up your environment for the OCR feature module using Foxit PDF SDK for .NET Core.
System requirements
Platform: Windows, Linux (x64)
Programming Language: C, C++, Java, Python, C#, Node.js, Go
License Key requirement: ‘OCR’ module permission in the license key
SDK Version: Foxit PDF SDK for Windows (C++, Java, C#) 6.4 or higher; Foxit PDF SDK (C) 7.4 or higher; Foxit PDF SDK for Windows (Python) 8.3 or higher; Foxit PDF SDK for Linux x64 (C++, Java, C#, Python) 9.0 or higher; Foxit PDF SDK (Node.js) 10.0 or higher
Note:
For Linux platform, in some cases, particularly within a clean Docker environment, you may encounter an engine initialization failure due to the lack of certain libraries during the container setup. The ‘libFREngine.so‘ in the engine may lack ‘libgomp.so.1‘, which can cause this issue.
To resolve this issue, perform the following commands in Docker:
sudo apt-get update sudo apt-get install libgomp1
Trial Limit for SDK OCR Add-on Module
For the trial version, there are three trail limits that you should notice:
Allow 30 consecutive natural days to evaluate SDK from the first time of OCREngine initialization.
Allow up to 5000 pages to be converted using OCR from the first time of OCREngine initialization.
Trail watermarks will be generated on the PDF pages. This limit is used for all of the SDK modules.
OCR resource files
Please contact Foxit support team or sales team to get the OCR resource files package.
For Windows:
After getting the package for Windows, extract it to a desired directory (for example, extract the package to a directory named “ocr_addon“), and then you can see the resource files for OCR are as follows:
debugging_files: Resource files used for debugging the OCR project. These file(s) cannot be distributed.
language_resource_CJK: Resource files for CJK language, including: Chinese-Simplified, Chinese-Traditional, Japanese, and Korean.
language_resources_noCJK: Resource files for the languages except CJK, including: Basque, Bulgarian, Catalan, Croatian, Czech, Danish, Dutch, English, Estonian, Faeroese, Finnish, French, Galician, German, Greek, Hebrew, Hungarian, Icelandic, Italian, Latvian (Lettish), Lithuanian, Macedonian, Maltese, Norwegian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swedish, Thai, Turkish, Ukrainian.
win32_lib: 32-bit library resource files
win64_lib: 64-bit library resource files
readme.txt: A txt file for introducing the role of each folder in this directory, as well as how to use those resource files for OCR.
For Linux x64:
After getting the package for Linux, extract it to a desired directory (for example, extract the package to a directory named “ocr_addon_linux“), and then you can see the resource files for OCR are as follows:
Data: Data and resource files for following languages:
Chinese-Simplified, Chinese-Traditional, Japanese, Korean, Basque, Bulgarian, Catalan, Croatian, Czech, Danish, Dutch, English, Estonian, Faeroese, Finnish, French, Galician, German, Greek, Hebrew, Hungarian, Icelandic, Italian, Latvian (Lettish), Lithuanian, Macedonian, Maltese, Norwegian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swedish, Thai, Turkish, Ukrainian.
Bin: Library files for Linux x64.
How to run the OCR demo
Foxit PDF SDK for .Net Core (Windows and Linux x64) provides an OCR demo located in the “examples\simple_demo\ocr” folder to show you how to use Foxit PDF SDK to do OCR for a PDF page or a PDF document.
Build an OCR resource directory
Before running the OCR demo, you should first build an OCR resource directory, and then pass the directory to Foxit PDF SDK API OCREngine.Initialize to initialize OCR engine.
Note: Starting from version 10.1, Foxit PDF SDK has restructured the OCREngine.Initialize interface and added a new parameter, is_shared_cpu_cores_mode, to specify whether to use multi-process mode. When this parameter value is true, multi-process mode will be used during the OCR process, and when the value is false, single-process mode will be used.
For Windows:
To build an OCR resource directory on Windows, please follow the steps below:
Create a new folder to add the resources. For example, “D:/ocr_resources”.
Add the appropriate library resource based on the platform architecture.
For win32, copy all the files under “ocr_addon/win32_lib” folder to “D:/ocr_resources”.
For win64, copy all the files under “ocr_addon/win64_lib” folder to “D:/ocr_resources”.
Add the language resource.
For CJK (Chinese-Simplified, Chinese-Traditional, Japanese, and Korean), copy all the files under “ocr_addon/language_resource_CJK” folder to “D:/ocr_resources”.
For all other languages except CJK, copy all the files under “ocr_addon/language_resources_noCJK” folder to “D:/ocr_resources”.
For all the supported languages, copy all the files under “ocr_addon/language_resource_CJK” and “ocr_addon/language_resources_noCJK” folders to “D:/ocr_resources”.
(Optional) Add debugging file resource if you need to debug the demo.
For win32, copy the file(s) under “ocr_addon/debugging_files/win32” folder to “D:/ocr_resources”.
For win64, copy the file(s) under “ocr_addon/debugging_files/win64” folder to “D:/ocr_resources”.
Note: The debugging files should be exclusively used for testing purposes. So, you cannot distribute them.
For Linux x64:
To build an OCR resource directory on Linux, please follow the steps below:
Create a new folder to add the resources. For example, “/root/Desktop/ocr_resources”.
Copy the whole folders of “Data“, “Bin” under the “ocr_addon_linux” to “/root/Desktop/ocr_resources”.
Then, the OCR resource files path is set to “/root/Desktop/ocr_resources/Bin“.
Note: Before loading the resource files, please set the environment variable for loading the library, please execute: export LD_LIBRARY_PATH=/root/Desktop/ocr_resources/Bin.
Configure the demo
After building the OCR resource directory, configure the demo in the “examples\simple_demo\ocr\ocr.cs” file. Following will configure the demo in “ocr.cs” file on Windows for example. For Linux x64 platform, do the similar configuration with Windows.
Specify the OCR resource directory
Add the OCR resource directory as follows, which will be used to initialize the OCR engine.

Choose the language resource
You will need to set the language used by the OCR engine into the demo code. This is done with the OCREngine.SetLanguages method and is set to “English” by default.

(Optional) Set log for OCREngine
If you want to print the entire log of the OCR Engine, please uncomment the OCREngine.SetLogFile method as below:

Run the demo
Open a command prompt, navigate to “examples\simple_demo”, run “RunDemo.bat ocr” for 64-bit Windows for example. Once the demo runs successfully, the console will print the following by default:
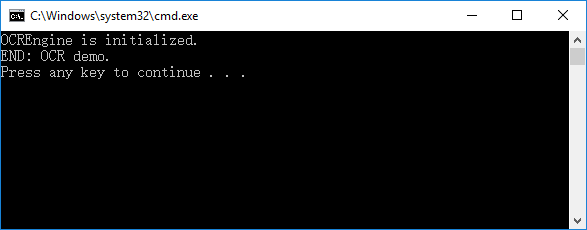
The demo will OCR the default document (“examples\simple_demo\input_files\ocr\AboutFoxit_ocr.pdf”) in four different ways, which will output four different PDFs in the output folder (“examples\simple_demo\output_files\ocr”):
OCR Editable PDF – ocr_doc_editable.pdf
OCR Searchable PDF – ocr_doc_searchable.pdf
OCR Editable PDF Page – ocr_page_editable.pdf
OCR Searchable PDF Page – ocr_page_searchable.pdf
Compliance
PDF Compliance
Foxit PDF SDK supports to convert PDF versions among PDF 1.3, PDF 1.4, PDF 1.5, PDF 1.6 and PDF 1.7. When converting to PDF 1.3, if the source document contains transparency data, then it will be converted to PDF 1.4 instead of PDF 1.3 (PDF 1.3 does not support transparency). If the source document does not contain any transparency data, then it will be converted to PDF 1.3 as expected.
PDF/A Compliance
PDF/A is an ISO-standardized version of the PDF specialized for use in the archiving and long-term preservation of electronic documents. PDF/A differs from PDF by prohibiting features unsuitable for long-term archiving, such as font linking (as opposed to font embedding), encryption, JavaScript, audio, video and so on.
Foxit PDF SDK provides APIs to convert a PDF to be compliance with PDF/A standard, or verify whether a PDF is compliance with PDF/A standard. It supports the PDF/A version including PDF/A-1a, PDF/A-1b, PDF/A-2a, PDF/A-2b, PDF/A-2u, PDF/A-3a, PDF/A-3b, PDF/A-3u (ISO 19005- 1, 19005 -2 and 19005-3).
PDF/E Compliance
PDF/E is an ISO-standardized version of the PDF specialized for the reliable exchange and archiving of engineering documents. It is designed for the creation, exchange, archiving, and printing documents used in engineering workflows.
From version 10.1, Foxit PDF SDK provides APIs to convert a PDF to be compliance with PDF/E standard or verify whether a PDF is compliance with PDF/E standard. It supports the PDF/E-1 version.
PDF/X Compliance
PDF/X is an ISO-standardized version of the PDF specialized for the exchange of graphics-intensive documents. It is mainly used to ensure consistency and predictability when printing files in fields such as design, drawing, engineering, and graphic arts.
From version 10.1, Foxit PDF SDK provides APIs to convert a PDF to be compliance with PDF/X standard or verify whether a PDF is compliance with PDF/X standard. It supports the PDF/X version including PDF/X-1a, PDF/X-3, PDF/X-4, PDF/X-4p.
Preflight Feature
From version 10.1, Foxit PDF SDK supports preflight feature, which allows users to utilize Foxit PDF SDK to get preflight keys and analyze or fixup PDF file.
This section will provide instructions on how to set up your environment for running the ‘compliance’ or ‘preflight’ demo.
System Requirements
Platform: Windows, Linux (x86 and x64), Mac
Programming Language: C, C++, Java, C#, Python, Objective-C, Node.js, Go
License Key requirement: ‘Compliance’ module permission in the license key
SDK Version: Foxit PDF SDK (C++, Java, C#, Objective-C) 6.4 or higher (for PDF Compliance, it requires Foxit PDF SDK 7.1 or higher); Foxit PDF SDK (C) 7.4 or higher; Foxit PDF SDK (Python) 8.3 or higher; Foxit PDF SDK (Node.js) 10.0 or higher
Note: For PDF/E, PDF/X, and preflight feature, it requires Foxit PDF SDK 10.1 or higher.
Compliance resource files
Please contact Foxit support team or sales team to get the Compliance resource files package.
After getting the package, extract it to a desired directory (for example, extract the package to a directory: “compliance/win” for Windows, “compliance/linux” for Linux, and “compliance/mac” for Mac), and then you can see the resource files for Compliance are as follows:
For Windows:
For Linux:
For Mac:
How to run the compliance or preflight demo
Before version 10.1, Foxit PDF SDK provides a compliance demo located in the “examples\simple_demo\compliance” folder to show you how to use Foxit PDF SDK to verify whether a PDF is compliance with PDF/A standard, and convert a PDF to be compliance with PDF/A standard, as well as convert PDF versions.
From version 10.1, Foxit PDF SDK provides two demos:
A compliance demo located in the “examples\simple_demo\compliance” folder to show you how to use Foxit PDF SDK to verify whether a PDF is compliance with PDF/A or PDF/E or PDF/X standard, and convert a PDF to be compliance with PDF/A or PDF/E or PDF/X standard, as well as convert PDF versions.
A preflight demo located in the “examples\simple_demo\preflight” folder to show you how to use Foxit PDF SDK to get preflight keys and analyze or fixup PDF file.
Build a compliance resource directory
Before running the compliance or preflight demo, you should first build a compliance resource directory, and then pass the directory to Foxit PDF SDK API ComplianceEngine.Initialize to initialize compliance engine.
Starting from version 10.0, the compliance resource files provide default thread-safety. For multithreading, the API ComplianceEngine.InitializeThreadContext should be called first for a new thread before using any other methods in the compliance add-on module.
Windows
To build a compliance resource directory on Windows, please follow the steps below:
Create a new folder to add the resources. For example, “D:/compliance_resources”.
Copy the whole folders of “ect“, “lang“, “var” under the “compliance/win” to “D:/compliance_resources”.
Add the appropriate library resource based on the platform architecture.
For win32, copy all the files under “compliance/win/lib/x86” folder to “D:/compliance_resources”.
For win64, copy all the files under “compliance/win/lib/x64” folder to “D:/compliance_resources”.
For example, use win64 platform architecture, then the compliance resource directory should be as follows:
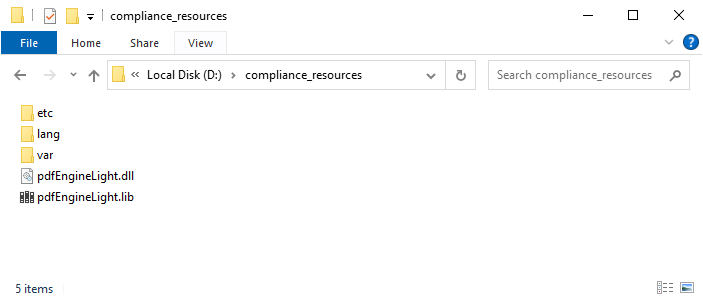
Linux (64-bit)
To build a compliance resource directory on Linux, please follow the steps below:
Create a new folder to add the resources. For example, “/root/Desktop/compliance_resources”.
Copy the whole folders of “ect“, “lang“, “var” under the “compliance/linux” to “/root/Desktop/compliance_resources”.
Copy all the files under “compliance/linux/lib/x64” folder to “/root/Desktop/compliance_resources”.
Then the compliance resource directory should be as follows:
Note: For Linux platform, you should put the compliance resource directory into the search path for system shared library before running the demo, otherwise ComplianceEngine.Initialize will fail.
For example, you can use the command (export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}: /root/Desktop/compliance_resources) to temporarily add the compliance resource directory to LD_LIBRARY_PATH.
Mac (64-bit)
For Mac platform, you can directly use the “compliance/mac” resource folder as the compliance resource directory.
Configure the demo
After building the compliance resource directory, configure the demo in the “examples\simple_demo\compliance\compliance.cs” for compliance demo or “examples\simple_demo\preflight\preflight.cs” for preflight demo.
This section takes Windows as an example to show you how to configure the demo in the “compliance.cs” or “preflight.cs” file. For Linux and Mac platforms, do the same configuration with Windows.
Specify the compliance resource directory
In the “compliance.cs” or “preflight.cs” file, add the compliance resource directory as follows, which will be used to initialize the compliance engine.
try
{
string input_file = input_path + "AboutFoxit.pdf";
// "compliance_resource_folder_path" is the path of compliance resource folder. Please refer to Developer Guide for more details.
string compliance_resource_folder_path = "D:/compliance _resources";
// If you use an authorization key for Foxit PDF SDK, please set a valid unlock code string to compliance_engine_unlockcode for ComplianceEngine.
// If you use an trial key for Foxit PDF SDK, just keep compliance_engine_unlockcode as an empty string.
string compliance_engine_unlockcode = "";
if (compliance_resource_folder_path.Length < 1) {
Console.WriteLine("compliance_resource_folder_path is still empty. Please set it with a valid path to compliance resource folder path.");
return ;
}
// Initialize compliance engine.
error_code = ComplianceEngine.Initialize(compliance_resource_folder_path, compliance_engine_unlockcode);
Note:
If you are using a trial key for Foxit PDF SDK, you do not need to authorize the compliance engine library.
If you are using an authorization key for Foxit PDF SDK, Foxit sales team will send you an extra unlock code for initializing compliance engine library. Pass the unlock code to the initialize function “ComplianceEngine.Initialize (compliance_resource_folder_path, compliance_engine_unlockcode)”.
(Optional) Set language for compliance engine (only for compliance demo)
ComplianceEngine.SetLanguage function is used to set language for compliance engine. The default language is “English”, and the supported languages are as follows:
“Czech”, “Danish”, “Dutch”, “English”, “French”, “Finnish”, “German”, “Italian”, “Norwegian”, “Polish”, “Portuguese”, “Spanish”, “Swedish”, “Chinese-Simplified”, “Chinese-Traditional”, “Japanese”, “Korean”.
For example, set the language to “Chinese-Simplified”:
// Set language. The default language is "English".
ComplianceEngine.SetLanguage("Chinese-Simplified");
(Optional) Set a temp folder for compliance engine (only for compliance demo)
ComplianceEngine.SetTempFolderPath function is used to set a temp folder to store several files for proper processing (e.g verifying or converting). If no custom temp folder is set by this function, the default temp folder in system will be used.
For example, set the path to “D:/compliance_temp” (should be a valid path).
// Set custom temp folder path for ComplianceEngine. ComplianceEngine.SetTempFolderPath(L"D:/compliance_temp");
Run the demo
Take compliance demo as an example, open a command prompt, navigate to “examples\simple_demo”, run “RunDemo.bat compliance” for 64-bit Windows for example. Once the demo runs successfully, the console will print the following by default:
The output files are located in “examples\simple_demo\output_files\compliance” folder.
Optimization
Optimization feature can reduce the size of PDF files to save disk space and make files easier to send and store, through compressing images, deleting redundant data, discarding useless user data and so on. From version 7.1, optimization module provides functions to compress the color/grayscale/monochrome images in PDF files to reduce the size of the PDF files.
Note: To use the Optimization feature, please make sure the license key has the permission of the ‘Optimization’ module.
Example:
How to optimize PDF files by compressing the color/grayscale/monochrome images
using System;
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.addon;
using foxit.addon.optimization;
using (PDFDoc doc = new PDFDoc("input_pdf_file"))
{
error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess)
{
Console.WriteLine("Document Load Error: {0}\n", error_code);
return;
}
using (Optimization_Pause pause = new Optimization_Pause(0, true))
using (OptimizerSettings settings = new OptimizerSettings())
{
Console.WriteLine("Optimized Start.\n");
Progressive progressive = Optimizer.Optimize(doc, settings, pause);
Progressive.State progress_state = Progressive.State.e_ToBeContinued;
while (Progressive.State.e_ToBeContinued == progress_state)
{
progress_state = progressive.Continue();
int percent = progressive.GetRateOfProgress();
Console.WriteLine("Optimize progress percent: {0}%\n", percent);
}
if (Progressive.State.e_Finished == progress_state)
{
doc.SaveAs("ImageCompression_Optimized.pdf", (int)PDFDoc.SaveFlags.e_SaveFlagRemoveRedundantObjects);
}
Console.WriteLine("Optimized Finish.\n");
}
}
HTML to PDF Conversion
For some large HTML files or a webpage which contain(s) many contents, it is not convenient to print or archive them directly. Foxit PDF SDK provides APIs to convert the online webpage or local HTML files like invoices or reports into PDF file(s), which makes them easier to print or archive. In the process of conversion from HTML to PDF, Foxit PDF SDK also supports to create and add PDF Tags based on the organizational structure of HTML.
For HTML to PDF module, it supports HTML5, CSS3 and JavaScript.
From version 7.6, Foxit PDF SDK supports to convert HTML to PDF on Linux platform. But for HTML to PDF engine (Linux), the version of libnss should be 3.22.
From version 8.1, the converted files (generated by HTML to PDF) can be provided in the form of file stream. If you want to use this feature, you should contact Foxit support team or sales team to get the latest engine files package.
From version 11.0, the HTML to PDF engine for Linux x86 will no longer receive updates or maintenance. The current version of the old engine will remain available for use, but new features will not be supported. In future releases, the engine may be deprecated.
This section will provide instructions on how to set up your environment for running the ‘html2pdf’ demo.
System requirements
Platform: Windows, Linux (x86 and x64), Mac
Programming Language: C, C++, Java, C#, Python, Objective-C, Node.js, Go
License Key requirement: ‘Conversion’ module permission in the license key
SDK Version: Foxit PDF SDK (C++, Java, C#, Objective-C) 7.0 or higher; Foxit PDF SDK (C) 7.4 or higher; Foxit PDF SDK (Python) 8.3 or higher; Foxit PDF SDK (Node.js) 10.0 or higher; Foxit PDF SDK (Go) 11.0
HTML to PDF engine files
Please contact Foxit support team or sales team to get the HTML to PDF engine files package.
After getting the package, extract it to a desired directory (for example, extract the package to a directory: “htmltopdf/win” for Windows, “htmltopdf/linux” for Linux, and “htmltopdf/mac” for Mac).
How to run the html2pdf demo
Foxit PDF SDK provides a html2pdf demo located in the “examples\simple_demo\html2pdf” folder to show you how to use Foxit PDF SDK to convert from html to PDF.
Prepare a HTML2PDF engine directory
Before running the html2pdf demo, you should first extract engine package to a desired directory (for example, extract the package to a directory: “D:/htmltopdf/win/” for Windows), and then pass the engine file path to the API foxit.addon.conversion.Convert.FromHTML to convert html to PDF file.
Configure the demo
For html2pdf demo, you can configure the demo in the “examples\simple_demo\html2pdf\html2pdf.cs” file, or you can configure the demo with parameters directly in a command prompt or a terminal. Following will configure the demo in “html2pdf.cs” file on Windows for example. For Linux and Mac platforms, do the same configuration with Windows.
Specify the html2pdf engine directory
In the “html2pdf.cs” file, add the path of the engine file “fxhtml2pdf.exe” as follows, which will be used to convert html files to PDF files.

(Optional) Specify cookies file path
Add the path of the cookies file exported from the web pages that you want to convert. For example,
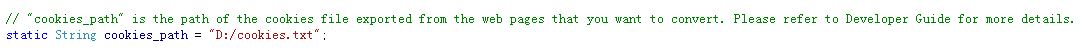
Run the demo
Run the demo without parameters
Open a command prompt, navigate to “examples\simple_demo”, run “RunDemo.bat html2pdf” for 64-bit Windows for example. Once the demo runs successfully, the console will print “Convert HTML to PDF successfully.”
Run the demo with parameters
Open a command prompt, navigate to “examples\simple_demo”, and run “RunDemo.bat html2pdf” for 64-bit Windows for example at first.
Then, in the command prompt, navigate to “examples\simple_demo\bin”, type “dotnet html2pdf.dll –help” to see how to use the parameters to execute the program.
For example, if you want to convert the URL web page “www.foxitsoftware.com” into a PDF with setting the page width to 900 points and the page height to 300 points, then you can run the following command:
dotnet html2pdf.dll -html www.foxitsoftware.com -w 900 -h 300
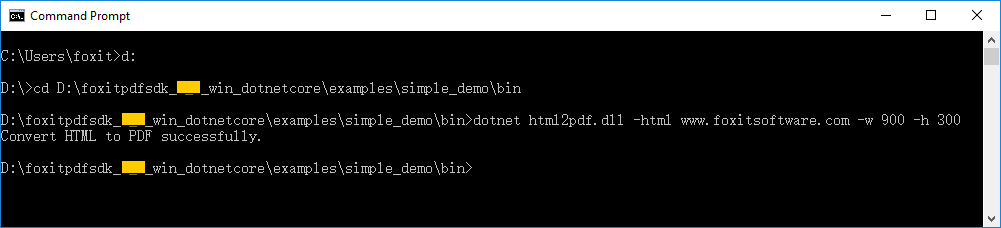
After running successfully, the output PDF file will be generated in the “examples\simple_demo\output_files\html2pdf” folder.
Parameters Description
Basic Syntax:
html2pdf_xxx <-html <The url or html path>> <-o <output pdf path>> <-engine <htmltopdf engine path>>
[-w <page width>] [-h <page height>] [-ml <margin left>] [-mr <margin right>]
[-mt <margin top>] [-mb <margin bottom>] [-r <page rotation degree>] [-mode <page mode>] [-scale <scaling mode>] [-link <whether to convert link>]
[-tag <whether to generate tag>] [-bookmarks <whether to generate bookmarks>]
[-print_background <whether to print background>]
[-optimize_tag <whether to optimize tag tree>] [-media <media style>] [-encoding <HTML encoding format>] [-render_images <Whether to render images>]
[-remove_underline_for_link <Whether to remove underline for link>]
[-headerfooter <Whether to generate headerfooter>] [-headerfooter_title <headerfooter title>] [-headerfooter_url <headerfooter url>] [-bookmark_root_name <bookmark root name>] [-resize_objects <Whether to enable the JavaScripts related resizing of the objects>]
[-cookies <cookies file path>] [-timeout <timeout>] [–help<Parameter usage>]
Note:
<> required
[ ] optional
| Parameters | Description |
| –help | The usage description of the parameters. |
| -html | The url or html file path. For example, ‘-html www.foxitsoftware.com’. |
| -o | The path of the output PDF file. |
| -engine | The path of the engine file “fxhtml2pdf.exe”. |
| -w | The page width of the output PDF file in points. |
| -h | The page height of the output PDF file in points. |
| -r | The page rotation for the output PDF file. 0 : 0 degree. 1 : 90 degree. 2 : 180 degree. 3 : 270 degree. |
| -ml | The left margin of the pages for the output PDF file. |
| -mr | The right margin of the pages for the output PDF file. |
| -mt | The top margin of the pages for the output PDF file. |
| -mb | The bottom margin of the pages for the output PDF file. |
| -mode | The page mode for the output PDF file. 0 : Single page mode. 1 : Multiple pages mode. |
| -scale | The scaling mode. 0 : No need to scale pages. 1 : Scale pages. 2 : Enlarge page. |
| -link | Whether to convert links. ‘yes’ : Convert links. ‘no’ : No need to convert links. |
| -tag | Whether to generate tag. ‘yes’ : Generate tag. ‘no’ : No need to generate tag. |
| -bookmarks | Whether to generate bookmarks. ‘yes’ : Generate bookmarks . ‘no’ : No need to generate bookmarks. |
| -print_background | Whether to print background. ‘yes’ : Print bookmarks . ‘no’ : No need to print bookmarks. |
| -optimize_tag | Whether to optimize tag tree. ‘yes’ : Optimize tag tree . ‘no’ : No need to optimize tag tree. |
| -media | The media style. 0 : Screen media style. 1 : Print media style. |
| -encoding | The HTML encoding format. 0 : Auto encoding . 1-73 : Other encodings. |
| -render_images | Whether to render images. ‘yes’ : Render images. ‘no’ : No need to render images. |
| -remove_underline_for_link | Whether to remove underline for link. ‘yes’ : Remove underline for link. ‘no’ : No need to remove underline for link. |
| -headerfooter | Whether to generate headerfooter. ‘yes’ : Generate headerfooter. ‘no’ : No need to generate headerfooter. |
| -headerfooter_title | The headerfooter title. |
| -headerfooter_url | The headerfooter url. |
| -bookmark_root_name | The bookmark root name. |
| -resize_objects | Whether to enable the JavaScripts related resizing of the objects during rendering process. ‘yes’ : Enable. ‘no’ : Disable. |
| -cookies | The path of the cookies file exported from a URL that you want to convert. |
| -timeout | The timeout of loading webpages. |
How to work with Html2PDF API
using foxit; foxit.addon.conversion.HTML2PDFSettingData pdf_setting_data = new foxit.addon.conversion.HTML2PDFSettingData(); pdf_setting_data.is_convert_link = true; pdf_setting_data.is_generate_tag = true; pdf_setting_data.to_generate_bookmarks = true; pdf_setting_data.rotate_degrees = 0; pdf_setting_data.page_height = 640; pdf_setting_data.page_width = 900; pdf_setting_data.page_mode = foxit.addon.conversion.HTML2PDFSettingData.HTML2PDFPageMode.e_PageModeSinglePage; pdf_setting_data.scaling_mode = foxit.addon.conversion.HTML2PDFSettingData.HTML2PDFScaleMode.e_ScalingModeScale; pdf_setting_data.to_print_background = true; pdf_setting_data.to_optimize_tag_tree = false; pdf_setting_data.media_style = foxit.addon.conversion.HTML2PDFSettingData.HTML2PDFMediaStyle.e_MediaStyleScreen; ... foxit.addon.conversion.Convert.FromHTML(url_or_html, engine_path, cookies_path, pdf_setting_data, output_path, time_out);
How to get HTML data from stream and convert it to a PDF file
Defines a FileRead class inherited from FileReaderCallback used to get html data from stream or memory. And defines a FileWriter class inherited from FileWriterCallback used to do file writing. For the implementations of FileRead and FileWriter classes, please refer to the html2pdf demo in the “examples\simple_demo\html2pdf” folder.
Get html data from stream and set resources related to source html.
Call the foxit.addon.conversion.Convert.FromHTML function to convert it to a PDF file.
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using System.IO;
foxit.addon.conversion.HTML2PDFSettingData pdf_setting_data = new foxit.addon.conversion.HTML2PDFSettingData();
pdf_setting_data.page_height = 650;
pdf_setting_data.page_width = 950;
pdf_setting_data.is_to_page_scale = false;
pdf_setting_data.page_margin = new RectF(18, 18, 18, 18);
pdf_setting_data.is_convert_link = true;
pdf_setting_data.rotate_degrees = 0;
pdf_setting_data.is_generate_tag = true;
pdf_setting_data.page_mode = foxit.addon.conversion.HTML2PDFSettingData.HTML2PDFPageMode.e_PageModeSinglePage;
pdf_setting_data.scaling_mode = foxit.addon.conversion.HTML2PDFSettingData.HTML2PDFScalingMode.e_ScalingModeScale;
pdf_setting_data.to_generate_bookmarks = true;
pdf_setting_data.encoding_format = 0;
pdf_setting_data.to_render_images = true;
pdf_setting_data.to_remove_underline_for_link = false;
pdf_setting_data.to_set_headerfooter = false;
pdf_setting_data.headerfooter_title = "";
pdf_setting_data.headerfooter_url = "";
pdf_setting_data.bookmark_root_name = "abcde";
pdf_setting_data.to_resize_objects = true;
pdf_setting_data.to_print_background = false;
pdf_setting_data.to_optimize_tag_tree = false;
pdf_setting_data.media_style = 0;
pdf_setting_data.to_load_active_content = false;
String output_path = output_directory + "html2pdf_filestream_result.pdf";
FileWriter filewrite = new FileWriter();
filewrite.LoadFile(output_path);
// "htmlfile" is the path of the html file to be loaded. For example: "C:/aaa.html". The method of "FromHTML" will load this file as a stream.
String htmlfile = "";
FileRead filereader = new FileRead();
filereader.loadFile(htmlfile, false);
// "htmlfilepng" is the path of the png resource file to be loaded. For example: "C:/aaa.png". set "htmlfilepng" in the related_resource_file of HTML2PDFRelatedResource.
String htmlfilepng = "";
FileRead filereader1 = new FileRead();
filereader1.loadFile(htmlfilepng, false);
//"relativefilepath" is the resource file's relative path. For example: "./aaa.png".
String relativefilepath = "";
foxit.addon.conversion.HTML2PDFRelatedResourceArray html2PDFRelatedResourceArray = new foxit.addon.conversion.HTML2PDFRelatedResourceArray();
foxit.addon.conversion.HTML2PDFRelatedResource html2PDFRelatedResource = new foxit.addon.conversion.HTML2PDFRelatedResource(filereader1, relativefilepath);
html2PDFRelatedResourceArray.Add(html2PDFRelatedResource);
foxit.addon.conversion.Convert.FromHTML(filereader, html2PDFRelatedResourceArray, engine_path, null,
pdf_setting_data, filewrite, 30);
Console.WriteLine("Convert HTML to PDF successfully by filestream!");
Office to PDF Conversion with third-party engines
From version 7.3, Foxit PDF SDK provides APIs to convert Microsoft Office documents (Word and Excel) into professional-quality PDF files on Windows platform.
From version 7.4, Foxit PDF SDK also supports to convert PowerPoint documents into PDF files on Windows platform.
From version 8.4, Foxit PDF SDK provides APIs to convert Microsoft Office documents (Word and Excel) into professional-quality PDF files on Linux platform (x86, x64 and armv8). Foxit PDF SDK for .NET Core just supports Windows and Linux x64 platforms.
For using this feature, please note that:
Make sure that Microsoft Office 2007 version or higher is already installed on your Windows system.
Before converting Excel to PDF, make sure that the default Microsoft virtual printer is already set on your Windows system.
For Linux x64, make sure that LibreOffice is already installed on your Linux system.
Note: When using LibreOffice 7.0 or a higher version, if you encounter an error like “An unknown error has occurred”, you can try to set an environment variable before running the program as follows:
"export URE_BOOTSTRAP=vnd.sun.star.pathname:/opt/libreoffice7.x/program/fundamentalrc"
Where, ‘x’ represents the LibreOffice version.
System requirements
Platform: Windows, Linux (x86, x64 and armv8)
Programming Language: C, C++, Python, Java, C#, Node.js, Go
License Key requirement: ‘Conversion’ module permission in the license key
SDK Version: Word and Excel (Foxit PDF SDK (C++, C#, Java) 7.3 or higher; Foxit PDF SDK (C) 7.4 or higher; Foxit PDF SDK (Python) 8.3 or higher); PowerPoint (Foxit PDF SDK (C, C++, C#, Java) 7.4 or higher; Foxit PDF SDK (Python) 8.3 or higher); Word/Excel/PowerPoint (Foxit PDF SDK (Node.js) 10.0 or higher); Word/Excel/PowerPoint (Foxit PDF SDK (Go) 11.0)
Example:
Note: For Linux x64, the parameter “engine_path” in the following sample code represents the path of LibreOffice engine. To get the installed path of LibreOffice, you can input the command “locate soffice.bin“ in a terminal, then the path will be shown, for example, “/usr/lib/libreoffice/program/soffice.bin“. Then the value of “engine_path” parameter is set to “/usr/lib/libreoffice/program”.
How to convert Word to PDF
Windows
using foxit;
…
// Make sure that SDK has already been initialized successfully.
string word_file_path = "test.doc";
string saved_pdf_path = "saved.pdf";
// Use default Word2PDFSettingData values.
using (foxit.addon.conversion.Word2PDFSettingData word_convert_setting_data = new foxit.addon.conversion.Word2PDFSettingData())
{
foxit.addon.conversion.Convert.FromWord(word_file_path, "", saved_pdf_path, word_convert_setting_data);
}
Linux x64
using foxit;
…
// Make sure that SDK has already been initialized successfully.
string word_file_path = "test.doc";
string saved_pdf_path = "saved.pdf";
// Use default Word2PDFSettingData values.
using (foxit.addon.conversion.Word2PDFSettingData word_convert_setting_data = new foxit.addon.conversion.Word2PDFSettingData())
{
foxit.addon.conversion.Convert.FromWord(word_file_path, "", saved_pdf_path, engine_path, word_convert_setting_data);
}
How to convert Excel to PDF
Windows
using foxit;
…
// Make sure that SDK has already been initialized successfully.
string excel_file_path= "test.xls";
string saved_pdf_path = "saved.pdf";
// Use default Excel2PDFSettingData values.
using (foxit.addon.conversion.Excel2PDFSettingData excel_convert_setting_data = new foxit.addon.conversion.Excel2PDFSettingData())
{
foxit.addon.conversion.Convert.FromExcel(excel_file_path, "", saved_pdf_path, excel_convert_setting_data);
}
Linux x64
using foxit;
…
// Make sure that SDK has already been initialized successfully.
string excel_file_path= "test.xls";
string saved_pdf_path = "saved.pdf";
// Use default Excel2PDFSettingData values.
using (foxit.addon.conversion.Excel2PDFSettingData excel_convert_setting_data = new foxit.addon.conversion.Excel2PDFSettingData())
{
foxit.addon.conversion.Convert.FromExcel(excel_file_path, "", saved_pdf_path, engine_path, excel_convert_setting_data);
}
How to convert PowerPoint to PDF
Windows
using foxit;
// Make sure that SDK has already been initialized successfully.
string ppt_file_path = "test.ppt";
string saved_pdf_path = "saved.pdf";
// Use default PowerPoint2PDFSettingData values.
using (foxit.addon.conversion.PowerPoint2PDFSettingData ppt_convert_setting_data = new foxit.addon.conversion.PowerPoint2PDFSettingData())
{
foxit.addon.conversion.Convert.FromPowerPoint(ppt_file_path, "", saved_pdf_path, ppt_convert_setting_data);
}
Linux x64
using foxit;
// Make sure that SDK has already been initialized successfully.
string ppt_file_path = "test.ppt";
string saved_pdf_path = "saved.pdf";
// Use default PowerPoint2PDFSettingData values.
using (foxit.addon.conversion.PowerPoint2PDFSettingData ppt_convert_setting_data = new foxit.addon.conversion.PowerPoint2PDFSettingData())
{
foxit.addon.conversion.Convert.FromPowerPoint(ppt_file_path, "", saved_pdf_path, engine_path, ppt_convert_setting_data);
}
Office to PDF Conversion with Foxit’s self-developed engines
From version 10.1, Foxit PDF SDK offers the capability to convert Microsoft Office documents (Word, Excel and PowerPoint) into professional-quality PDF files with Foxit’s self-developed engines. This feature is available through the Foxit PDF Conversion SDK on Windows platform.
From version 11.0, Foxit PDF SDK extends support for Office-to-PDF conversion with Foxit’s self-developed engines to Linux x86/x64 platforms.
System requirements
Platform: Windows, Linux (x86, and x64)
Programming Language: C, C++, Python, Java, C#, Node.js, Go
License Key requirement: ‘Office2PDF’ module permission in the license key
SDK Version: Foxit PDF SDK for Windows 10.1 or higher; Foxit PDF SDK for Linux x86/x64 11.0
Office to PDF resource files (Foxit PDF Conversion SDK )
Please contact Foxit support team or sales team to get the Foxit PDF Conversion SDK (C++).
After getting Foxit PDF Conversion SDK package, extract it to a desired directory, for example, extract the package to a directory: “D:/foxitpdfconversionsdk_*_win/” for Windows, and “/home/user/Desktop/foxitpdfconversionsdk_*_Linux/” for Linux x86/x64.
How to run the office2pdf demo using Foxit PDF Conversion SDK
Before running the office2pdf demo in the “examples\simple_demo\office2pdf” folder using Foxit PDF Conversion SDK, you should first add the Foxit PDF Conversion SDK library in the demo code, for example:
// If you want to convert office files to PDF whitout other third-party engines, you can use the Office2PDF module. string library_path = "D:/foxitpdfconversionsdk_*_win/lib/fpdfconversionsdk_win32.dll";
Then, specify the office2pdf resource data files:
// A valid path of a folder which contains resource data files. office2pdf_setting_data.resource_folder_path = " D:/foxitpdfconversionsdk_*_win/res/office2pdf ";
Finally, run the demo following the steps as the other demos.
How to convert office files to PDF with Foxit’s self-developed engines
using foxit;
...
// If you want to convert office files to PDF whitout other third-party engines, you can use the Office2PDF module.
string library_path = ""; // Path of Foxit PDF Conversion SDK library, please ensure the path is valid.
// Initialize the Office2PDF module.
foxit.addon.conversion.office2pdf.Office2PDF.Initialize(library_path);
// Use default Office2PDFSettingData values.
using (foxit.addon.conversion.office2pdf.Office2PDFSettingData office2pdf_setting_data = new foxit.addon.conversion.office2pdf.Office2PDFSettingData())
{
// A valid path of a folder which contains resource data files.
office2pdf_setting_data.resource_folder_path = "";
// Convert Word file to PDF file.
saved_pdf_path = output_path + "word2pdf_result_foxit.pdf";
foxit.addon.conversion.office2pdf.Office2PDF.ConvertFromWord(word_file_path, "", saved_pdf_path, office2pdf_setting_data);
// Convert Excel file to PDF file.
saved_pdf_path = output_path + "excel2pdf_result_foxit.pdf";
foxit.addon.conversion.office2pdf.Office2PDF.ConvertFromExcel(excel_file_path, "", saved_pdf_path, office2pdf_setting_data);
// Convert PowerPoint file to PDF file.
saved_pdf_path = output_path + "ppt2pdf_result_foxit.pdf";
foxit.addon.conversion.office2pdf.Office2PDF.ConvertFromPowerPoint(ppt_file_path, "", saved_pdf_path, office2pdf_setting_data);
}
// Release the Office2PDF module.
foxit.addon.conversion.office2pdf.Office2PDF.Release();
Output Preview
From version 7.4, Foxit PDF SDK supports output preview feature which can preview color separations and test different color profiles.
System requirements
Platform: Windows, Linux (x86 and x64), Mac (x64)
Programming Language: C, C++, Java, C#, Python, Objective-C, Node.js, Go
License Key requirement: valid license key
SDK Version: Foxit PDF SDK (C, C++, Java, C#, Objective-C) 7.4 or higher; Foxit PDF SDK (Python) 8.3 or higher; Foxit PDF SDK (Node.js) 10.0 or higher; Foxit PDF SDK (Go) 11.0
How to run the output preview demo
Before running the output preview demo in the “examples\simple_demo\output_preview” folder, you should first set the folder path of “res\icc_profile” in the SDK package to the variable default_icc_folder_path. For example:
// "default_icc_folder_path" is the path of the folder which contains default icc profile files. Please refer to Developer Guide for more details. string default_icc_folder_path = "E:\foxitpdfsdk_X_X_win_dotnetcore/res/icc_profile";
Then, run the demo following the steps as the other demos.
How to do output preview using Foxit PDF SDK
using foxit.common;
using foxit.pdf;
// Make sure that SDK has already been initialized successfully.
// Set folder path which contains default icc profile files.
Library.SetDefaultICCProfilesPath(default_icc_folder_path);
// Load a PDF document; Get a PDF page and parse it.
// Prepare a Renderer object and the matrix for rendering.
using (OutputPreview output_preview = new OutputPreview(pdf_doc))
{
string simulation_icc_file_path = input_path + "icc_profile/USWebCoatedSWOP.icc";
output_preview.SetSimulationProfile(simulation_icc_file_path);
output_preview.SetShowType(OutputPreview.ShowType.e_ShowAll);
StringArray process_plates = output_preview.GetPlates(OutputPreview.ColorantType.e_ColorantTypeProcess);
StringArray spot_plates = output_preview.GetPlates(OutputPreview.ColorantType.e_ColorantTypeSpot);
// Set check status of process plate to be true, if there's any process plate.
for (uint i = 0; i<process_plates.GetSize(); i++)
{
output_preview.SetCheckStatus(process_plates.GetAt(i), true);
}
// Set check status of spot plate to be true, if there's any spot plate.
for (uint i = 0; i<spot_plates.GetSize(); i++)
{
output_preview.SetCheckStatus(spot_plates.GetAt(i), true);
}
using (foxit.common.Bitmap preview_bitmap = output_preview.GeneratePreviewBitmap(pdf_page, display_matrix, renderer))
{
...// Use preview bitmap or save it.
}
}
Combination
Combination feature is used to combine several PDF files into one PDF file.
How to combine several PDF files into one PDF file
using foxit.pdf;
// Make sure that SDK has already been initialized successfully.
CombineDocumentInfoArray info_array = new CombineDocumentInfoArray();
info_array.Add(new CombineDocumentInfo(input_path + "AboutFoxit.pdf", ""));
info_array.Add(new CombineDocumentInfo(input_path + "Annot_all.pdf", ""));
info_array.Add(new CombineDocumentInfo(input_path + "SamplePDF.pdf", ""));
String savepath = output_path + "Test_Combined.pdf";
int option = (int)(Combination.CombineDocsOptions.e_CombineDocsOptionBookmark | Combination.CombineDocsOptions.e_CombineDocsOptionAcroformRename |
Combination.CombineDocsOptions.e_CombineDocsOptionStructrueTree | Combination.CombineDocsOptions.e_CombineDocsOptionOutputIntents |
Combination.CombineDocsOptions.e_CombineDocsOptionOCProperties | Combination.CombineDocsOptions.e_CombineDocsOptionMarkInfos |
Combination.CombineDocsOptions.e_CombineDocsOptionPageLabels | Combination.CombineDocsOptions.e_CombineDocsOptionNames |
Combination.CombineDocsOptions.e_CombineDocsOptionObjectStream | Combination.CombineDocsOptions.e_CombineDocsOptionDuplicateStream);
Progressive progress = Combination.StartCombineDocuments(savepath, info_array, option, null);
Progressive.State progress_state = Progressive.State.e_ToBeContinued;
while (Progressive.State.e_ToBeContinued == progress_state)
{
progress_state = progress.Continue();
}
PDF Portfolio
PDF portfolios are a combination of files with different formats. Portfolio file itself is a PDF document, and files with different formats can be embedded into this kind of PDF document.
System requirements
Platform: Windows, Linux, Mac
Programming Language: C, C++, Java, C#, Python, Objective-C, Node.js, Go
License Key requirement: valid license key
SDK Version: Foxit PDF SDK (C, C++, Java, C#, Objective-C) 7.6 or higher; Foxit PDF SDK (Python) 8.3 or higher; Foxit PDF SDK (Node.js) 10.0 or higher; Foxit PDF SDK (Go) 11.0
Example:
How to create a new and blank PDF portfolio
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
// Make sure that SDK has already been initialized successfully.
using (Portfolio new_portfolio = Portfolio.CreatePortfolio())
{
// Set properties, add file/folder node to the new portfolio.
...
// Get portfolio PDF document object.
using (PDFDoc portfolio_pdf_doc = new_portfolio.GetPortfolioPDFDoc())
{
...
}
}
How to create a Portfolio object from a PDF portfolio
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
// Make sure that SDK has already been initialized successfully.
using (PDFDoc portfolio_pdf_doc = new PDFDoc("portfolio.pdf"))
{
ErrorCode error_code = portfolio_pdf_doc.Load(null);
if (ErrorCode.e_ErrSuccess == error_code)
{
if (portfolio_pdf_doc.IsPortfolio())
{
using (Portfolio existed_portfolio = Portfolio.CreatePortfolio(portfolio_pdf_doc))
{
...
}
}
}
}
How to get portfolio nodes
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
// Make sure that SDK has already been initialized successfully.
// Portfolio object has been created, assume it is named "portfolio".
...
using (PortfolioNode root_node = portfolio.GetRootNode())
{
using (PortfolioFolderNode root_folder = new PortfolioFolderNode(root_node))
{
using (PortfolioNodeArray sub_nodes = root_folder.GetSortedSubNodes())
{
for (uintindex = 0; index < sub_nodes.GetSize(); index++)
{
using (PortfolioNode node = sub_nodes.GetAt(index))
{
switch (node.GetNodeType())
{
case PortfolioNode::e_TypeFolder:
{
using (PortfolioFolderNode folder_node = new PortfolioFolderNode(node))
{
// Use PortfolioFolderNode's getting method to get some properties.
...
PortfolioNodeArray sub_nodes_2 = folder_node.GetSortedSubNodes();
...
break;
}
}
case PortfolioNode::e_TypeFile:
{
using (PortfolioFileNode file_node = new PortfolioFileNode(node))
{
// Get file specification object from this file node, and then get/set information from/to this file specification object.
using (FileSpec file_spec = file_node.GetFileSpec())
{
...
break;
}
}
}
}
}
}
}
}
}
How to add file node or folder node
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
// Make sure that SDK has already been initialized successfully.
// Portfolio object has been created, and the root folder node has been retrieved, assume it is named "root_folder".
...
// Add file from path.
string path_to_a_file = "directory/Sample.txt";
using (PortfolioFileNode new_file_node_1 = root_folder.AddFile(path_to_a_file))
{
// User can update properties of file specification for new_file_node_1 if necessary.
...
}
// Add file from MyStreamCallback which is inherited from StreamCallback and implemented by user.
MyStreamCallback my_stream_callback = new MyStreamCallback();
using (PortfolioFileNode new_file_node_2 = root_folder.AddFile(my_stream_callback, "file_name"))
{
// Please get file specification of new_file_node_2 and update properties of the file specification by its setting methods.
...
}
// Add a loaded PDF file.
// Open and load a PDF file, assume it is named "test_pdf_doc".
...
using (PortfolioFileNode new_file_node_3 = root_folder.AddPDFDoc(test_pdf_doc, "pdf_file_name"))
{
// User can update properties of file specification for new_file_node_3 if necessary.
...
}
// Add a sub folder in root_folder.
using (PortfolioFolderNode new_sub_foldernode = root_folder.AddSubFolder("Sub Folder-1") {
// User can add file or folder node to new_sub_foldernode.
...
}
How to remove a node
using foxit; using foxit.common; using foxit.common.fxcrt; using foxit.pdf; // Make sure that SDK has already been initialized successfully. // Remove a child folder node from its parent folder node. parent_folder_node.RemoveSubNode(child_folder_node); // Remove a child file node from its parent folder node. parent_folder_node.RemoveSubNode(child_file_node);
Table Maker
From version 8.4, Foxit PDF SDK supports to add table to PDF files.
System requirements
Platform: Windows, Mac, Linux
Programming Language: C, C++, Java, C#, Python, Objective-C, Node.js, Go
License Key requirement: ‘TableMaker’ module permission in the license key
SDK Version: Foxit PDF SDK (C, C++, C#, Java, Python, Objective-C) 8.4 or higher; Foxit PDF SDK (Node.js) 10.0 or higher; Foxit PDF SDK (Go) 11.0
How to add table to a PDF document
Foxit PDF SDK provides an electronictable demo located in the “examples\simple_demo\electronictable” folder to show you how to use Foxit PDF SDK to add table to PDF document.
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.addon;
using foxit.addon.tablegenerator;
...
// Add a spreadsheet with 4 rows and 3 columns
int index = 0;
using (TableCellDataArray cell_array = new TableCellDataArray())
{
for (int row = 0; row < 4; row++)
{
using (RichTextStyle style = new RichTextStyle())
using (TableCellDataColArray col_array = new TableCellDataColArray())
{
for (int col = 0; col < 3; col++)
{
string cell_text = GetTableCellText(index);
SetTableTextStyle(index++, style);
Image image = new Image();
using (TableCellData cell_data = new TableCellData(style, cell_text, image, new RectF()))
{
col_array.Add(cell_data);
}
}
cell_array.Add(col_array);
}
}
float page_width = pdf_page.GetWidth();
float page_height = pdf_page.GetHeight();
TableBorderInfo outside_border_left = new TableBorderInfo();
outside_border_left.line_width = 1;
outside_border_left.table_border_style = TableBorderInfo.TableBorderStyle.e_TableBorderStyleSolid;
TableBorderInfo outside_border_right = new TableBorderInfo();
outside_border_right.line_width = 1;
outside_border_right.table_border_style = TableBorderInfo.TableBorderStyle.e_TableBorderStyleSolid;
TableBorderInfo outside_border_top = new TableBorderInfo();
outside_border_top.line_width = 1;
outside_border_top.table_border_style = TableBorderInfo.TableBorderStyle.e_TableBorderStyleSolid;
TableBorderInfo outside_border_bottom = new TableBorderInfo();
outside_border_bottom.line_width = 1;
outside_border_bottom.table_border_style = TableBorderInfo.TableBorderStyle.e_TableBorderStyleSolid;
TableBorderInfo inside_border_row_info = new TableBorderInfo();
inside_border_row_info.line_width = 1;
inside_border_row_info.table_border_style = TableBorderInfo.TableBorderStyle.e_TableBorderStyleSolid;
TableBorderInfo inside_border_col_info = new TableBorderInfo();
inside_border_col_info.line_width = 1;
inside_border_col_info.table_border_style = TableBorderInfo.TableBorderStyle.e_TableBorderStyleSolid;
using (RectF rect = new RectF(100, 550, page_width - 100, page_height - 100))
using (TableData data = new TableData(rect, 4, 3, outside_border_left, outside_border_right, outside_border_top, outside_border_bottom, inside_border_row_info, inside_border_col_info, new TableCellIndexArray(), new FloatArray(), new FloatArray()))
{
TableGenerator.AddTableToPage(pdf_page, data, cell_array);
}
}
...
Accessibility
From version 8.4, Foxit PDF SDK supports to tag PDF files.
System requirements
Platform: Windows, Mac, Linux
Programming Language: C, C++, Java, C#, Python, Objective-C, Node.js, Go
License Key requirement: ‘Accessibility’ module permission in the license key
SDK Version: Foxit PDF SDK (C, C++, C#, Java, Python, Objective-C) 8.4 or higher; Foxit PDF SDK (Node.js) 10.0 or higher; Foxit PDF SDK (Go) 11.0
How to tag a PDF document
Foxit PDF SDK provides a taggedpdf demo located in the “examples\simple_demo\taggedpdf” folder to show you how to use Foxit PDF SDK to tag a PDF document.
using foxit.common;
using foxit.common.fxcrt;
using foxit.addon.conversion;
using foxit.pdf;
using foxit.addon.accessibility;
...
using(pdf_doc=newPDFDoc(input_file))
{
pdf_doc.Load(null);
using(vartaggedpdf=newTaggedPDF(pdf_doc))
{
Progressiveprogressive=taggedpdf.StartTagDocument(null);
Progressive.Statestate=Progressive.State.e_ToBeContinued;
while(state==Progressive.State.e_ToBeContinued)
{
state=progressive.Continue();
}
}
pdf_doc.SaveAs(output_file,0);
}
...
PDF to Office Conversion
Foxit PDF SDK provides APIs to convert PDF files to MS office suite formats while maintaining the layout and format of your original documents on Windows and Linux platforms.
System requirements
Platform: Windows, Linux
Programming Language: C, C++, Java, Python, C#, Node.js, Go
License Key requirement: ‘PDF2Office’ module permission in the license key
SDK Version: Foxit PDF SDK for Windows (C, C++, Java, Python, C#) 9.0 or higher; Foxit PDF SDK for Linux (C, C++, Java, Python, C#) 9.1 or higher; Foxit PDF SDK (Node.js) 10.0 or higher; Foxit PDF SDK (Go) 11.0
PDF to Office resource files
Please contact Foxit support team or sales team to get the PDF to Office resource files package naming Foxit PDF Conversion SDK (C++).
The required Foxit PDF Conversion SDK versions for different Foxit PDF SDK versions are shown in the table below.
| Foxit PDF SDK Version | Required Foxit PDF Conversion SDK Version |
| 9.0/9.1 | 1.4 |
| 9.2 | 1.5 |
| 10.0 | 2.0 |
| 10.1 | 2.1 |
| 11.0 | 3.0 |
After getting Foxit PDF Conversion SDK package, extract it to a desired directory (for example, extract the package to a directory: “foxitpdfconversionsdk_*_win/” for Windows, and “foxitpdfconversionsdk_*_linux/” for Linux x64), and then you can see the resource files for PDF to Office are as follows:
For Windows:
For Linux:
How to run the pdf2office demo
Foxit PDF SDK for Windows provides a pdf2office demo located in the “examples\simple_demo\pdf2office” folder to show you how to use Foxit PDF SDK to convert PDF files to MS office suite formats.
Prepare a PDF2Office resource directory
Before running the pdf2office demo, you should first extract the PDF to Office resource files (Foxit PDF Conversion SDK) package to a desired directory (for example, extract the package to a directory: “C:/foxitpdfconversionsdk_*_win/” for Windows), and then pass the engine file located in “lib” folder to the API PDF2Office.Initialize to initialize PDF2Office engine.
Configure the demo
For pdf2office demo, you can configure the demo in the “examples\simple_demo\pdf2office\pdf2office.cs” file. Following will configure the demo in “pdf2office.cs” file on Windows for example. For Linux platform, do the similar configuration with Windows.
Specify the pdf2office engine directory
In the “pdf2office.cs” file, add the path of the engine file “pdf2office” as follows, which will be used to convert PDF files to office files.
// Please ensure the path is valid.
PDF2Office.Initialize("C:/foxitpdfconversionsdk_*_win/lib/fpdfconversionsdk_win32.dll", "");
(Optional) Specify whether to enable machine learning-based recognition functionality
setting_data.enable_ml_recognition = false;
(Optional) Specify the page range to be converted
setting_data.page_range = new Range();
(Optional) Specify whether to convert the comments in the PDF documents
setting_data.include_pdf_comments = true;
(Optional) Specify whether to retain the page layout for PDF to Word conversion
setting_data.word_setting_data.enable_retain_page_layout = false;
Note: Starting from version 10.1, the PDF to Office Conversion engine supports a timeout parameter. This parameter defines the maximum time allowed for the conversion process to complete. If the conversion exceeds the specified time, it will be terminated. The timeout must be a non-negative value. A value of 0 disables the timeout, allowing the conversion to proceed without any time limitation.
Run the demo
Once you run the demo successfully, the console will print the following by default:
The output files are located in “examples\simple_demo\output_files\pdf2office” folder.
How to work with PDF2office API
using System;
using System.IO;
using System.Runtime.InteropServices;
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.addon.conversion.pdf2office;
public class CustomConvertCallback : ConvertCallback
{
public CustomConvertCallback() { }
public override bool NeedToPause()
{
return true;
}
public override void ProgressNotify(int converted_count, int total_count)
{
}
}
using (CustomConvertCallback callback = new CustomConvertCallback())
{
using (Progressive progressive = PDF2Office.StartConvertToWord(input_path + "word.pdf", null, output_path + "pdf2word_result.docx", setting_data, callback))
{
if (progressive.GetRateOfProgress() != 100)
{
Progressive.State state = Progressive.State.e_ToBeContinued;
while (Progressive.State.e_ToBeContinued == state)
{
state = progressive.Continue();
}
}
Console.WriteLine("Convert PDF file to Word format file with path.");
}
}
using (CustomConvertCallback callback = new CustomConvertCallback())
{
using (Progressive progressive = PDF2Office.StartConvertToExcel(input_path + "excel.pdf", null, output_path + "pdf2excel_result.xlsx", setting_data, callback))
{
if (progressive.GetRateOfProgress() != 100)
{
Progressive.State state = Progressive.State.e_ToBeContinued;
while (Progressive.State.e_ToBeContinued == state)
{
state = progressive.Continue();
}
}
Console.WriteLine("Convert PDF file to Excel format file with path.");
}
}
using (CustomConvertCallback callback = new CustomConvertCallback())
{
using (Progressive progressive = PDF2Office.StartConvertToPowerPoint(input_path + "powerpoint.pdf", null, output_path + "pdf2powerpoint_result.pptx", setting_data, callback))
{
if (progressive.GetRateOfProgress() != 100)
{
Progressive.State state = Progressive.State.e_ToBeContinued;
while (Progressive.State.e_ToBeContinued == state)
{
state = progressive.Continue();
}
}
Console.WriteLine("Convert PDF file to PowerPoint format file with path.");
}
}
DWG to PDF Conversion
From version 10.0, Foxit PDF SDK supports to convert DWG files to PDF files. If you want to use this feature, you should contact Foxit support team or sales team to get the engine files package.
System requirements
Platform: Windows, Linux (x86 and x64), Mac(x64)
Programming Language: C, C++, Java, C#, Python, Objective-C, Node.js, Go
License Key requirement: ‘DWG2PDF’ module permission in the license key
SDK Version: Foxit PDF SDK (C, C++, Java, C#, Python, Objective-C, Node.js) 10.0 or higher; Foxit PDF SDK (Go) 11.0
DWG To PDF engine files
Please contact Foxit support team or sales team to get the DWG to PDF engine files package.
After getting the package, extract it to the desired directory. For example, extract the package to a directory: “D:/dwgtopdf/win” for Windows, “dwgtopdf/linux” for Linux, and “dwgtopdf/mac” for Mac.
How to run the dwg2pdf demo
Before running the dwg2pdf demo in the “examples\simple_demo\dwg2pdf” folder, you should first add the dwg2pdf engine file in the demo code, for example:
// "engine_path" is the path of the engine file "dwg2pdf" which is used to convert dwg to pdf. Please refer to Developer Guide for more details. static String engine_path = "D:/dwgtopdf/win";
Note: For Linux (x86 and x64) and Mac x64, before running the demo, you should configure environment variables.
For Linux x86 and x64, add the path of the dwg2pdf engine file to LD_LIBRARY_PATH environment variable.
export LD_LIBRARY_PATH=/dwgtopdf/linux:$LD_LIBRARY_PATH
For Mac x64, add the path of the dwg2pdf engine file to DWG_ENGINE_PATH environment variable.
export DWG_ENGINE_PATH=/dwgtopdf/mac
Then, run the demo following the steps as the other demos.
How to convert DWG to PDF
using foxit; … // Make sure that SDK has already been initialized successfully. foxit.addon.conversion.DWG2PDFSettingData pdf_setting_data = new foxit.addon.conversion.DWG2PDFSettingData(); pdf_setting_data.export_flags = foxit.addon.conversion.DWG2PDFSettingData.DWG2PDFExportFlags.e_FlagEmbededTTF; pdf_setting_data.export_hatches_type = foxit.addon.conversion.DWG2PDFSettingData.DWG2PDFExportHatchesType. e_DWG2PDFExportHatchesTypeBitmap; pdf_setting_data.other_export_hatches_type = foxit.addon.conversion.DWG2PDFSettingData.DWG2PDFExportHatchesType. e_DWG2PDFExportHatchesTypeBitmap; pdf_setting_data.gradient_export_hatches_type = foxit.addon.conversion.DWG2PDFSettingData. DWG2PDFExportHatchesType.e_DWG2PDFExportHatchesTypeBitmap; pdf_setting_data.searchable_text_type = foxit.addon.conversion.DWG2PDFSettingData.DWG2PDFSearchableTextType. e_DWG2PDFSearchableTextTypeNoSearch; pdf_setting_data.is_active_layout = false; pdf_setting_data.paper_width = 640; pdf_setting_data.paper_heigh = 900; ... foxit.addon.conversion.Convert.FromDWG(engine_path, dwg_file_path, output_path, pdf_setting_data); …
OFD
OFD (Open Fixed-layout Document) is an open layout document standard formulated by the Chinese government. It is mainly used for scenarios such as electronic official documents, archival storage and exchange. Its purpose is to provide a document format that does not depend on specific software or hardware, ensuring the consistency of document display effects across different devices and platforms.
OFD files not only contain structured data but also support rich graphic elements. They can precisely define the layout and content of the document, including text, images, vector graphics, annotations, etc. The characteristics of the XML format make it easy to understand, process and render, greatly enhancing the interoperability of the document.
OFD files have significant advantages in document integrity, security, and interoperability:
Document Authenticity: Supports digital signatures to ensure reliable document sources.
Information Security: Supports encryption to protect sensitive information from unauthorized access.
Interactivity: Supports interactive features such as form fields and digital signatures, enhancing the user experience.
To handle OFD files, you need to use viewer or editor software that supports the OFD standard. These tools can display, edit, convert, and print OFD documents.
In summary, as a domestic document format standard, OFD has been widely used in government agencies and enterprises. Especially in the case of formal documents that need to be preserved for a long time and legally protected, OFD provides a choice that is more suitable for China’s national conditions than traditional PDF. In addition, with the development of technology, OFD is also constantly improving and evolving to meet the growing digital office needs.
System requirements
Platform: Windows, Linux (x64 and armv8)
Programming Language: C, C++, Java, C#, Python, Node.js, Go
License Key requirement: ‘OFD’ module permission in the license key
SDK Version: Foxit PDF SDK (C, C++, Java, C#, Python, Node.js) 10.0 or higher; Foxit PDF SDK (Go) 11.0
OFD engine file
Please contact Foxit support team or sales team to get the OFD engine file package.
After getting the package, extract it to the desired directory. For example, extract the package to a directory: “D:/ofd/win” for Windows, and “ofd/linux64” for Linux x64.
How to run the ofd demo
Before running the ofd demo in the “examples\simple_demo\ofd” folder, you should first add the ofd engine file in the demo code, for example:
// "engine_path" is the path of ofd engine file. Please refer to Developer Guide for more details. string engine_path = "D:/ofd/win/x64"; // For Windows x64
Then, run the demo following the steps as the other demos.
How to implement the conversion between OFD file and PDF file
using foxit.addon.conversion;
using foxit.addon.ofd;
...
// Initialize OFD engine.
Library.InitializeOFDEngine(engine_path);
String src_ofd_path = input_path + "wm_txttiled.ofd";
String src_pdf_path = input_path + "test.pdf";
using (OFDConvertParam convert_param = new OFDConvertParam())
{ // Convert OFD document to PDF document.
foxit.addon.conversion.Convert.FromOFD(src_ofd_path, "", output_path + "ofd2pdf.pdf", convert_param);
// Convert PDF document to OFD document.
foxit.addon.conversion.Convert.ToOFD(src_pdf_path, "", output_path + "pdf2ofd.ofd", convert_param);
}
// Release OFD engine.
Library.ReleaseOFDEngine();
How to render OFD page
using foxit.common;
using foxit.addon.ofd;
using foxit.common.fxcrt;
...
// Initialize OFD engine.
Library.InitializeOFDEngine(engine_path);
// Render OFD document to bitmap.
string render_file_path = input_path + "content_flag.ofd";
using (OFDDoc doc = new OFDDoc(render_file_path, ""))
{
using (OFDPage ofd_page = doc.GetPage(0))
{
// Get the size of the page.
float w = ofd_page.GetWidth();
float h = ofd_page.GetHeight();
using (Bitmap bitmap = new Bitmap((int)w, (int)h, Bitmap.DIBFormat.e_DIBArgb, System.IntPtr.Zero, 0))
{
// Get the display matrix of the page.
Matrix2D matrix_1 = ofd_page.GetDisplayMatrix(0, 0, (int)w, (int)h, Rotation.e_Rotation0);
OFDRenderer ofd_render = new OFDRenderer(bitmap);
Progressive progressive = ofd_render.StartRender(ofd_page, matrix_1);
string save_name = output_path + "renderBitmap.bmp";
// Add the bitmap to image and save the image.
foxit.common.Image image = new foxit.common.Image();
image.AddFrame(bitmap);
image.SaveAs(save_name);
System.GC.Collect();
ofd_render.Release();
ofd_page.Release();
doc.Release();
}
}
}
// Release OFD engine.
Library.ReleaseOFDEngine();
Paragraph Editing
Foxit PDF SDK offers a versatile set of tools for developers to fine-tune and customize text in PDF documents. The paragraph editing module provides complex adjustments, joining, and splitting functions that allow users to have precise control over the content of the document. The features are complemented by an intuitive UI implementation that facilitates efficient editing, ensuring a seamless and customized experience for managing text paragraphs.
The paragraph editing functionality revolves around two core modules, the ParagraphEditing module, and the JoinSplit module.
The ParagraphEditing module is designed to offer a variety of text editing operations, enabling users to easily perform the following actions according to their specific requirements:
Insert Text: Insert new content at specific locations, allowing for customization of the document’s precise layout.
Delete Text: Delicately remove paragraphs or characters, enabling highly customized content trimming.
Modify Text: Adjust existing text, including its content and formatting, to suit different editing styles.
Format Adjustment: Support fine adjustments to paragraph formats and text styles, allowing for more accurate typesetting.
The JoinSplit module contains four vital operation types to support more complex text processing requirements:
Join: Integrate multiple text blocks, enhancing content layout and overall document consistency.
Split: Finely split text blocks, providing flexibility to manage various sections of the document.
Link: Establish connections between text blocks, ensuring consistency in associated content.
Unlink: Disconnect links between text blocks, offering more control over editing.
System requirements
Platform: Windows, Linux, Mac
Programming Language: C, C++, Java, C#, Python, Objective-C, Go
License Key requirement: ‘AdvEdit’ module permission in the license key
SDK Version: Foxit PDF SDK (C, C++, Java, C#, Python, Objective-C) 10.0 or higher; Foxit PDF SDK (Go) 11.0
How to work with paragraph editing
using foxit;
using foxit.common;
using foxit.common.fxcrt;
using foxit.pdf;
using foxit.addon.pageeditor
...
class FxParagraphEditingProviderCallback : ParagraphEditingProviderCallback
{
private int page_index = 0;
public FxParagraphEditingProviderCallback(int index)
{
page_index = index;
}
public override void Release()
{
}
public override void AddUndoItem(ParagraphEditingUndoItem undo_item)
{
}
public override RectF GetClientRect(PDFDoc document)
{
return new RectF();
}
public override int GetCurrentPageIndex(PDFDoc document)
{
return 0;
}
public override RectF GetPageRect(PDFDoc document, int page_index)
{
PDFPage page = document.GetPage(page_index);
int width = (int)(page.GetWidth());
int height = (int)(page.GetHeight());
RectF rect = new RectF(); ;
rect.left = 0;
rect.bottom = height;
rect.right = width;
rect.top = 0;
page.Dispose();
return rect;
}
public override IntPtr GetPageViewHandle(PDFDoc document, int page_index)
{
return IntPtr.Zero; ;
}
public override RectF GetPageVisibleRect(PDFDoc document, int page_index)
{
return new RectF();
}
public override Matrix2D GetRenderMatrix(PDFDoc document, int page_index)
{
PDFPage page = document.GetPage(page_index);
int width = (int)page.GetWidth();
int height = (int)page.GetHeight();
Matrix2D matrix = page.GetDisplayMatrix(0, 0, width, height, page.GetRotation());
page.Dispose();
return matrix;
}
public override Rotation GetRotation(PDFDoc document, int page_index)
{
return Rotation.e_Rotation0;
}
public override float GetScale(PDFDoc document, int page_index)
{
return 1;
}
public override Int32Array GetVisiblePageIndexArray(PDFDoc document)
{
Int32Array page_array = new Int32Array();
page_array.Add(0);
return page_array;
}
public override bool GotoPageView(PDFDoc document, int page_index, float left, float top)
{
return true;
}
public override void InvalidateRect(PDFDoc document, int page_index, RectFArray invalid_rects)
{
}
public override void NotifyTextInputReachLimit(PDFDoc document, int page_index)
{
}
public override void SetDocChangeMark(PDFDoc document)
{
}
};
...
using (PDFPage page = doc.GetPage(0))
{
page.StartParse(0, null, false);
float height = page.GetHeight();
string output_dir = output_path;
int index = page.GetIndex();
using (FxParagraphEditingProviderCallback callback = new FxParagraphEditingProviderCallback(index))
{
using (ParagraphEditingMgr editingMgr = new ParagraphEditingMgr(callback, doc))
{
//Paragraph_editing
ParagraphEditing editing = editingMgr.GetParagraphEditing();
if (editing.IsEmpty() == true)
return;
editing.Activate();
editing.StartEditing(0, new PointF(95, height - 728), new PointF(95, height - 728));
editing.SetFontSize(24);
editing.SetUnderline(true);
editing.InsertText("InsertText_Paragraph_editing");
editing.Deactivate();
output_path = output_dir + "Paragraph_editing.pdf";
doc.SaveAs(output_path, (int)PDFDoc.SaveFlags.e_SaveFlagNoOriginal);
//Join&split
JoinSplit joinSplit = editingMgr.GetJoinSplit();
joinSplit.Activate();
joinSplit.OnLButtonDown(0, new PointF(289, 659));
joinSplit.OnLButtonUp(0, new PointF(289, 659));
joinSplit.SplitBoxes();
joinSplit.Deactivate();
output_path = output_dir + "Split_Boxes.pdf";
doc.SaveAs(output_path, (int)PDFDoc.SaveFlags.e_SaveFlagNoOriginal);
joinSplit.Activate();
joinSplit.OnLButtonDown(0, new PointF(307, height - 637));
joinSplit.OnLButtonUp(0, new PointF(307, height - 637));
joinSplit.OnLButtonDown(0, new PointF(307, height - 453));
joinSplit.OnLButtonUp(0, new PointF(307, height - 453));
joinSplit.JoinBoxes();
joinSplit.Deactivate();
output_path = output_dir + "Join_Boxes.pdf";
doc.SaveAs(output_path, (int)PDFDoc.SaveFlags.e_SaveFlagNoOriginal);
}
}
}
3D Rendering
3D Rendering in PDFs helps convert 3D models into 2D images or animations, which can be embedded in the document. The 3D models can be created using specialized 3D modeling software or CAD (Computer-Aided Design) software and can then be rendered into a 2D format that can be easily viewed within a PDF.
3D Annotation is a feature that allows users to add contextual information to specific parts of these 3D models within the PDF. The annotations can include text, images, and even links to external resources, providing more detailed information and insights about the model.
System requirements
Platform: Windows
Programming Language: C, C++, Java, C#, Python, Go
License Key requirement: ‘3D’ module permission in the license key
SDK Version: Foxit PDF SDK (C, C++, Java, C#, Python) 10.0 or higher; Foxit PDF SDK (Go) 11.0
How to display the 3D annotation
using foxit.addon.pdf3d; // Load PDF document. ... PDF3DContext pdf_context = new PDF3DContext(pdf_doc); // Get the 3d annotation instance array. PDF3DAnnotInstanceArray annot_data_arr = pdf_context.GetPage3DAnnotArray(0); if (annot_data_arr.GetSize() == 0) return; // Class parameter. PDF3DAnnotInstance annotData = annot_data_arr.GetAt(0); // Activate the canvas to display the 3d annotation. Pass in a window handle to embed canvas. annotData.ActivateCanvas(window handle);
How to set render mode and controller
using foxit.addon.pdf3d; // Rotate to view 3D annotations. annotData.SetController(PDF3DAnnotInstance.PDF3DController.e_ControllerRotate); // Render 3D annotations as transparent. annotData.SetRenderMode(PDF3DAnnotInstance.PDF3DRenderMode.e_RenderModeTransparent);
FAQ
How do I get text objects in a specified position of a PDF and change the contents of the text objects?
To get text objects in a specified position of a PDF and change the contents of the text objects using Foxit PDF SDK, you can follow the steps below:
Open a PDF file.
Load PDF pages and get the page objects.
Use PDFPage.GetGraphicsObjectAtPoint to get the text object at a certain position. Note: use the page object to get rectangle to see the position of the text object.
Change the contents of the text objects and save the PDF document.
Following is the sample code:
using foxit.common;
using foxit.pdf;
using foxit.pdf.graphics;
using foxit.common.fxcrt;
...
namespace graphics_objectsCS
{
class graphics_objects
{
...
static bool ChangeTextObjectContent()
{
string input_file = input_path + "AboutFoxit.pdf";
using (var doc = new PDFDoc(input_file))
{
ErrorCode error_code = doc.Load(null);
if (error_code != ErrorCode.e_ErrSuccess)
{
Console.WriteLine("The Doc {0} Error: {1}", input_file, error_code);
return false;
}
try
{
// Get original shading objects from the first PDF page.
using (var original_page = doc.GetPage(0))
{
using (var progressive = original_page.StartParse((int)PDFPage.ParseFlags.e_ParsePageNormal, null, false))
{
PointF pointf = new PointF(92, 762);
using (var arr = original_page.GetGraphicsObjectsAtPoint(pointf, 10, GraphicsObject.Type.e_TypeText))
{
for (int i = 0; i < arr.GetSize(); i++)
{
using (var graphobj = arr.GetAt(i))
{
using (var textobj = graphobj->GetTextObject())
{
textobj.SetText("Foxit Test");
}
}
}
}
original_page.GenerateContent();
}
}
string output_directory = output_path + "graphics_objects/";
string output_file = output_directory + "After_revise.pdf";
doc.SaveAs(output_file, (int)PDFDoc.SaveFlags.e_SaveFlagNormal);
}
catch (System.Exception e)
{
Console.WriteLine(e.Message);
}
return true;
}
}
...
}
}
Can I change the DPI of an embedded TIFF image?
No, you cannot change it. The DPI of the images in PDF files is static, so if the images already exist, Foxit PDF SDK does not have functions to change its DPI.
The solution is that you can use third-party library to change the DPI of an image, and then add it to the PDF file.
Note: Foxit PDF SDK provides a function “Image.SetDPIs” which can set the DPI property of an image object. However, it only supports the images that are created by Foxit PDF SDK or created by function “Image.AddFrame“, and it does not support the image formats of JPX, GIF and TIF.
Why do I encounter “Fail to initialize the engine file or cannot load the engine file” for OCR and DWG2PDF modules on Windows 7 when running the corresponding simple demos, even if the engine files have been upgraded to the latest and the simple demos have configured the engine path correctly?
For Windows 7, you need to copy the dll files starting with api–ms-win* and the ucrtbase.dll in the engine directory to the system directory.
If you are using a 32-bit engine and running on a 32-bit system, you need to copy the api-ms-win*.dll files and ucrtbase.dll from the engine directory to “C:/Windows/System32”.
If you are using a 32-bit engine and running on a 64-bit system, you need to copy the api-ms-win*.dll files and ucrtbase.dll from the engine directory to “C:/Windows/SysWOW64”.
If you are using a 64-bit engine, you need to copy the api-ms-win*.dll files and ucrtbase.dll from the engine directory to “C:/Windows/System32”.
How to run the Office2PDF functionality in Windows services?
To run the Office2PDF functionality in Windows services, you need to configure the Office Component Services and permissions.
Take the Word component as an example.
Press Win+R, and then type Dcomcnfg to open Component Services, find [Component Services] -> [Computers] -> [My Computer] -> [DCOM Config] -> [Microsoft Word 97-2003 Document], right-click it and select Properties. Choose [Identity], and set it to “The interactive user“.
Note: if you can’t find [Microsoft Word 97-2003 Document] with Dcomcnfg command, you can try to use the “comexp.msc -32” command.
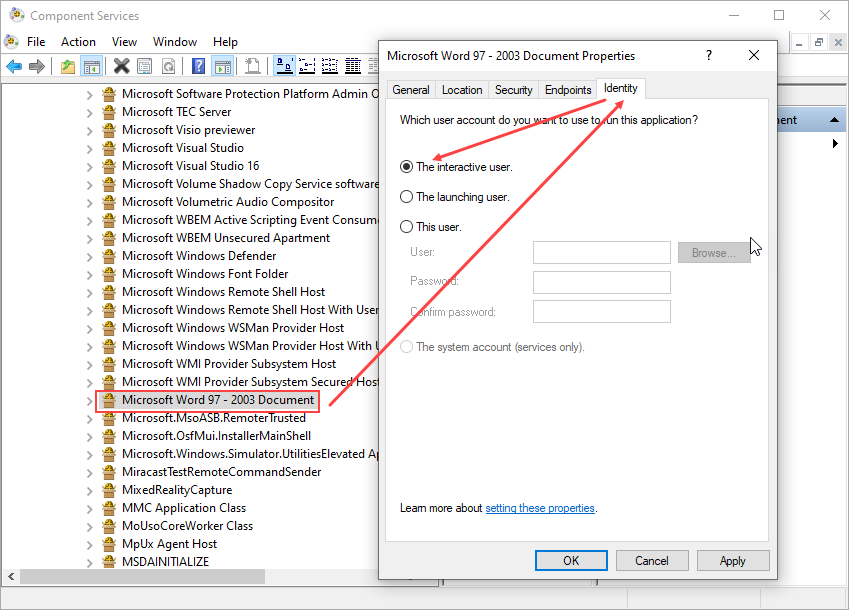
Set permissions. click [Security], set the [Launch and Activation Permissions] and [Access Permissions] to Customize. Click Edit, and add the current login account of the system and enable all permissions.
After finishing the above settings, the Word2PDF functionality can be run in the Windows services.
Why do I encounter “system.badimageformatexception: an attempt was made to load a program with an incorrect format” when using Foxit PDF SDK for .NET Core?
The error occurs because the application architecture and the dynamic library architecture of the GSDK do not match. You need to set the application’s /platform to x86, x64 or AnyCPU, and then use the GSDK dynamic library with the corresponding architecture.
Note: The support for AnyCPU platform target started from the SDK 10.0 version.
How to resolve the namespace conflicts when Using the NuGet packages of Foxit PDF SDK and Foxit PDF Conversion SDK together?
When both the Foxit PDF SDK and Foxit PDF Conversion SDK NuGet packages are loaded into a single Dotnet Core project, namespace conflicts may occur. To resolve this issue, you need to modify two target files:
$(NuGetPackageRoot)foxit.sdk.dotnet\$(version)\build\netcoreapp2.1\Foxit.SDK.Dotnet.targets
$(NuGetPackageRoot)foxit.pdfconversionsdk.dotnet\$(version)\build\netcoreapp2.1\Foxit.PDFConversionSDK.Dotnet.targets
In these files, add the <Aliases> element at an appropriate location and set aliases for the target assemblies. This will create different aliases for the two SDKs, thus avoiding namespace conflicts.
Please note, $(NuGetPackageRoot) is the root directory of the NuGet package, and $(version) is the current version of the NuGet package.
Below is a configuration screenshot of the Foxit PDF SDK and Foxit PDF Conversion SDK.
Foxit PDF SDK configuration
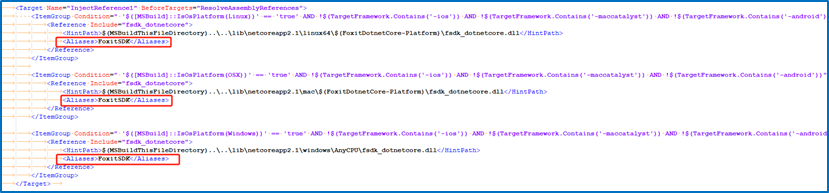
Foxit PDF Conversion SDK configuration

After setting the alias, you can use the extern alias directive in your code to reference the assembly. For example:
extern alias FoxitSDK; extern alias FoxitConversionSDK; using pdf = FoxitSDK::foxit.pdf; using pdf2office = FoxitConversionSDK::foxit.conversion.pdf2office;
In this way, even if both SDKs are used in the same project, you can independently access each SDK’s classes and methods by using aliases, thus avoiding name conflicts.
Appendix
Supported JavaScript List
Objects’ property or method
| Object | Properites/Method Names | Minimum Supported SDK Version |
| annotation properties | alignment | V7.0 |
| author | V7.0 | |
| contents | V7.0 | |
| creationDate | V7.0 | |
| fillColor | V7.0 | |
| hidden | V7.0 | |
| modDate | V7.0 | |
| name | V7.0 | |
| opacity | V7.0 | |
| page | V7.0 | |
| readOnly | V7.0 | |
| rect | V7.0 | |
| richContents | V7.1 | |
| rotate | V7.0 | |
| strokeColor | V7.0 | |
| textSize | V7.0 | |
| type | V7.0 | |
| AP | V9.0 | |
| arrowBegin | V9.0 | |
| arrowEnd | V9.0 | |
| attachIcon | V9.0 | |
| attachment | V9.0 | |
| borderEffectIntensity | V9.0 | |
| borderEffectStyle | V9.0 | |
| callout | V9.0 | |
| caretSymbol | V9.0 | |
| dash | V9.0 | |
| delay | V9.0 | |
| doc | V9.0 | |
| doCaption | V9.0 | |
| gestures | V9.0 | |
| inReplyTo | V9.0 | |
| intent | V9.0 | |
| leaderExtend | V9.0 | |
| leaderLength | V9.0 | |
| lineEnding | V9.0 | |
| lock | V9.0 | |
| noteIcon | V9.0 | |
| noView | V9.0 | |
| point | V9.0 | |
| points | V9.0 | |
| popupOpen | V9.0 | |
| popupRect | V9.0 | |
| V9.0 | ||
| quads | V9.0 | |
| refType | V9.0 | |
| richDefaults | V9.0 | |
| seqNum | V9.0 | |
| soundIcon | V9.0 | |
| style | V9.0 | |
| subject | V9.0 | |
| textFont | V9.0 | |
| toggleNoView | V9.0 | |
| vertices | V9.0 | |
| width | V9.0 | |
| annotation method | destroy | V7.0 |
| getProps | V9.0 | |
| setProps | V9.0 | |
| getStateInModel | V9.0 | |
| app properties | activeDocs | V4.0 |
| calculate | V4.0 | |
| formsVersion | V4.0 | |
| fs | V4.0 | |
| fullscreen | V4.0 | |
| language | V4.2 | |
| platform | V4.0 | |
| runtimeHighlight | V4.0 | |
| viewerType | V4.0 | |
| viewerVariation | V4.0 | |
| viewerVersion | V4.0 | |
| printerNames | V8.4 | |
| runtimeHighlightColor | V8.4 | |
| constants | V8.4 | |
| app methods | alert | V4.0 |
| beep | V4.0 | |
| browseForDoc | V4.0 | |
| clearInterval | V4.0 | |
| clearTimeOut | V4.0 | |
| launchURL | V4.0 | |
| mailMsg | V4.0 | |
| response | V4.0 | |
| setInterval | V4.0 | |
| setTimeOut | V4.0 | |
| popUpMenu | V4.0 | |
| execDialog | V8.4 | |
| execMenuItem | V8.4 | |
| newDoc | V8.4 | |
| openDoc | V8.4 | |
| popUpMenuEx | V8.4 | |
| addMenuItem | V8.4 | |
| addSubMenu | V8.4 | |
| addToolButton | V8.4 | |
| removeToolButton | V8.4 | |
| listMenuItems | V8.4 | |
| trustedFunction | V8.4 | |
| beginPriv | V8.4 | |
| endPriv | V8.4 | |
| color properties | black | V4.0 |
| blue | V4.0 | |
| cyan | V4.0 | |
| dkGray | V4.0 | |
| gray | V4.0 | |
| green | V4.0 | |
| ltGray | V4.0 | |
| magenta | V4.0 | |
| red | V4.0 | |
| transparent | V4.0 | |
| white | V4.0 | |
| yellow | V4.0 | |
| color methods | convert | V4.0 |
| equal | V4.0 | |
| document properties | author | V4.0 |
| baseURL | V4.0 | |
| bookmarkRoot | V7.0 | |
| calculate | V4.0 | |
| Collab | V4.0 | |
| creationDate | V4.0 | |
| creator | V4.0 | |
| delay | V4.0 | |
| dirty | V4.0 | |
| documentFileName | V4.0 | |
| external | V4.0 | |
| filesize | V4.0 | |
| icons | V4.0 | |
| info | V4.0 | |
| keywords | V4.0 | |
| modDate | V4.0 | |
| numFields | V4.0 | |
| numPages | V4.0 | |
| pageNum | V4.0 | |
| path | V4.0 | |
| producer | V4.0 | |
| subject | V4.0 | |
| title | V4.0 | |
| URL | V8.4 | |
| dataObjects | V8.4 | |
| hostContainer | V8.4 | |
| templates | V8.4 | |
| media | V8.4 | |
| dynamicXFAForm | V8.4 | |
| mouseX | V8.4 | |
| mouseY | V8.4 | |
| pageWindowRect | V8.4 | |
| securityHandler | V8.4 | |
| zoom | V8.4 | |
| zoomType | V8.4 | |
| layout | V8.4 | |
| xfa | V8.4 | |
| document methods | addAnnot | V7.0 |
| addField | V4.0 | |
| addIcon | V4.0 | |
| calculateNow | V4.0 | |
| deletePages | V4.0 | |
| exportAsFDF | V4.0 | |
| flattenPages | V7.1 | |
| getAnnot | V7.0 | |
| getAnnots | V7.0 | |
| getField | V4.0 | |
| getIcon | V4.0 | |
| getNthFieldName | V4.0 | |
| getOCGs | V4.0 | |
| getPageBox | V4.0 | |
| getPageNthWord | V4.0 | |
| getPageNthWordQuads | V4.0 | |
| getPageNumWords | V4.0 | |
| getPageRotation | V7.0 | |
| getPrintParams | V4.0 | |
| getURL | V4.0 | |
| importAnFDF | V4.0 | |
| insertPages | V6.2 | |
| mailForm | V4.0 | |
| V4.0 | ||
| removeField | V4.0 | |
| replacePages | V6.2 | |
| resetForm | V4.0 | |
| submitForm | V4.0 | |
| mailDoc | V4.0 | |
| addWatermarkFromFile | V8.4 | |
| addWatermarkFromText | V8.4 | |
| getPageLabel | V8.4 | |
| setPageLabels | V8.4 | |
| gotoNamedDest | V8.4 | |
| saveAs | V8.4 | |
| scroll | V8.4 | |
| setPageTabOrder | V8.4 | |
| selectPageNthWord | V8.4 | |
| syncAnnotScan | V8.4 | |
| getAnnot3D | V8.4 | |
| getAnnots3D | V8.4 | |
| addLink | V8.4 | |
| removeLinks | V8.4 | |
| getLinks | V8.4 | |
| importIcon | V8.4 | |
| removeIcon | V8.4 | |
| addWeblinks | V8.4 | |
| removeWeblinks | V8.4 | |
| closeDoc | V8.4 | |
| exportDataObject | V8.4 | |
| importDataObject | V8.4 | |
| removeDataObject | V8.4 | |
| getDataObject | V8.4 | |
| embedDocAsDataObject | V8.4 | |
| createTemplate | V8.4 | |
| removeTemplate | V8.4 | |
| getTemplate | V8.4 | |
| exportAsText | V8.4 | |
| importTextData | V8.4 | |
| exportAsXFDF | V8.4 | |
| importAnXFDF | V8.4 | |
| exportAsXFDFStr | V8.4 | |
| extractPages | V8.4 | |
| movePage | V8.4 | |
| newPage | V8.4 | |
| getOCGOrder | V8.4 | |
| setOCGOrder | V8.4 | |
| setPageBoxes | V8.4 | |
| setPageRotations | V8.4 | |
| setPageTransitions | V9.1 | |
| getPageTransition | V9.1 | |
| event properties | change | V4.0 |
| changeEx | V4.0 | |
| commitKey | V4.0 | |
| fieldFull | V4.0 | |
| keyDown | V4.0 | |
| modifier | V4.0 | |
| name | V4.0 | |
| rc | V4.0 | |
| selEnd | V4.0 | |
| selStart | V4.0 | |
| shift | V4.0 | |
| source | V4.0 | |
| target | V4.0 | |
| targetName | V4.0 | |
| type | V4.0 | |
| value | V4.0 | |
| willCommit | V4.0 | |
| event methods | add | V9.0 |
| field properties | alignment | V4.0 |
| borderStyle | V4.0 | |
| buttonAlignX | V4.0 | |
| buttonAlignY | V4.0 | |
| buttonFitBounds | V4.0 | |
| buttonPosition | V4.0 | |
| buttonScaleHow | V4.0 | |
| buttonScaleWhen | V4.0 | |
| calcOrderIndex | V4.0 | |
| charLimit | V4.0 | |
| comb | V4.0 | |
| commitOnSelChange | V4.0 | |
| currentValueIndices | V4.0 | |
| defaultValue | V4.0 | |
| doNotScroll | V4.0 | |
| doNotSpellCheck | V4.0 | |
| delay | V4.0 | |
| display | V4.0 | |
| doc | V4.0 | |
| editable | V4.0 | |
| exportValues | V4.0 | |
| hidden | V4.0 | |
| fileSelect | V4.0 | |
| fillColor | V4.0 | |
| lineWidth | V4.0 | |
| highlight | V4.0 | |
| multiline | V4.0 | |
| multipleSelection | V4.0 | |
| name | V4.0 | |
| numItems | V4.0 | |
| page | V4.0 | |
| password | V4.0 | |
| V4.0 | ||
| radiosInUnison | V4.0 | |
| readonly | V4.0 | |
| rect | V4.0 | |
| required | V4.0 | |
| richText | V4.0 | |
| rotation | V4.0 | |
| strokeColor | V4.0 | |
| style | V4.0 | |
| textColor | V4.0 | |
| textFont | V4.0 | |
| textSize | V4.0 | |
| type | V4.0 | |
| userName | V4.0 | |
| value | V4.0 | |
| valueAsString | V4.0 | |
| richValue | V9.0 | |
| submitName | V9.0 | |
| field methods | browseForFileToSubmit | V4.0 |
| buttonGetCaption | V4.0 | |
| buttonGetIcon | V4.0 | |
| buttonSetCaption | V4.0 | |
| buttonSetIcon | V4.0 | |
| checkThisBox | V4.0 | |
| clearItems | V4.0 | |
| defaultIsChecked | V4.0 | |
| deleteItemAt | V4.0 | |
| getArray | V4.0 | |
| getItemAt | V4.0 | |
| insertItemAt | V4.0 | |
| isBoxChecked | V4.0 | |
| isDefaultChecked | V4.0 | |
| setAction | V4.0 | |
| setFocus | V4.0 | |
| setItems | V4.0 | |
| buttonImportIcon | V9.0 | |
| getLock | V9.0 | |
| setLock | V9.0 | |
| signatureGetModifications | V9.0 | |
| signatureGetSeedValue | V9.0 | |
| signatureInfo | V9.0 | |
| signatureSetSeedValue | V9.0 | |
| signatureSign | V9.0 | |
| signatureValidate | V9.0 | |
| global methods | setPersistent | V4.0 |
| Icon properties | name | V4.0 |
| util methods | printd | V4.0 |
| printf | V4.0 | |
| printx | V4.0 | |
| scand | V4.0 | |
| iconStreamFromIcon | V9.0 | |
| identity properties | loginName | V4.2 |
| name | V4.2 | |
| corporation | V4.2 | |
| V4.2 | ||
| collab properties | user | V6.2 |
| ocg properties | name | V6.2 |
| ocg methods | setAction | V6.2 |
| bookmark properties | color | V8.4 |
| open | V8.4 | |
| name | V8.4 | |
| parent | V8.4 | |
| children | V8.4 | |
| language | V8.4 | |
| style | V8.4 | |
| platform | V8.4 | |
| bookmark methods | createChild | V8.4 |
| insertChild | V8.4 | |
| execute | V8.4 | |
| setAction | V8.4 | |
| remove | V8.4 | |
| certificate properties | binary | V8.4 |
| issuerDN | V8.4 | |
| keyUsage | V8.4 | |
| MD5Hash | V8.4 | |
| privateKeyValidityEnd | V8.4 | |
| privateKeyValidityStart | V8.4 | |
| SHA1Hash | V8.4 | |
| serialNumber | V8.4 | |
| subjectCN | V8.4 | |
| subjectDN | V8.4 | |
| validityEnd | V8.4 | |
| validityStart | V8.4 | |
| RDN properties | c | V8.4 |
| cn | V8.4 | |
| e | V8.4 | |
| l | V8.4 | |
| o | V8.4 | |
| ou | V8.4 | |
| st | V8.4 | |
| security properties | handlers | V9.0 |
| security methods | getHandler | V9.0 |
| importFromFile | V9.0 | |
| securityHandler properties | appearances | V9.0 |
| isLoggedIn | V9.0 | |
| loginName | V9.0 | |
| loginPath | V9.0 | |
| name | V9.0 | |
| uiName | V9.0 | |
| securityHandler methods | login | V9.0 |
| logout | V9.0 | |
| newUser | V9.0 | |
| signatureInfo properties | objValidity | V9.0 |
| idValidity | V9.0 | |
| idPrivValidity | V9.0 | |
| docValidity | V9.0 | |
| byteRange | V9.0 | |
| verifyHandlerUIName | V9.0 | |
| verifyHandlerName | V9.0 | |
| verifyDate | V9.0 | |
| subFilter | V9.0 | |
| statusText | V9.0 | |
| status | V9.0 | |
| reason | V9.0 | |
| name | V9.0 | |
| mdp | V9.0 | |
| location | V9.0 | |
| handlerUIName | V9.0 | |
| handlerUserName | V9.0 | |
| handlerName | V9.0 | |
| dateTrusted | V9.0 | |
| date | V9.0 | |
| search properties | attachments | V9.0 |
| bookmarks | V9.0 | |
| docText | V9.0 | |
| ignoreAccents | V9.0 | |
| markup | V9.0 | |
| matchCase | V9.0 | |
| matchWholeWord | V9.0 | |
| maxDocs | V9.0 | |
| proximity | V9.0 | |
| stem | V9.0 | |
| wordMatching | V9.0 | |
| ignoreAsianCharacterWidth | V9.0 | |
| search methods | query | V9.0 |
| addIndex | V9.0 | |
| removeIndex | V9.0 | |
| link properties | borderColor | V8.4 |
| borderWidth | V8.4 | |
| highlightMode | V8.4 | |
| rect | V8.4 | |
| link methods | setAction | V8.4 |
| app.media properties | align | V8.4 |
| canResize | V8.4 | |
| ifOffScreen | V8.4 | |
| over | V8.4 | |
| windowType | V8.4 | |
| app.media methods | createPlayer | V8.4 |
| openPlayer | V8.4 | |
| doc.media methods | getOpenPlayers | V8.4 |
| Playerargs properties | doc | V8.4 |
| annot | V8.4 | |
| rendition | V8.4 | |
| URL | V8.4 | |
| mimeType | V8.4 | |
| settings | V8.4 | |
| events | V8.4 | |
| MediaPlayer properties | isOpen | V8.4 |
| isPlaying | V8.4 | |
| settings | V8.4 | |
| visible | V8.4 | |
| MediaPlayer methods | close | V8.4 |
| play | V8.4 | |
| seek | V8.4 | |
| stop | V8.4 | |
| MediaSettings properties | autoPlay | V8.4 |
| baseURL | V8.4 | |
| bgColor | V8.4 | |
| bgOpacity | V8.4 | |
| duration | V8.4 | |
| floating | V8.4 | |
| page | V8.4 | |
| repeat | V8.4 | |
| showUI | V8.4 | |
| visible | V8.4 | |
| volume | V8.4 | |
| windowType | V8.4 | |
| floating properties | align | V8.4 |
| over | V8.4 | |
| canResize | V8.4 | |
| hasClose | V8.4 | |
| hasTitle | V8.4 | |
| title | V8.4 | |
| ifOffScreen | V8.4 | |
| rect | V8.4 | |
| eventListener methods | afterClose | V9.0 |
| afterPlay | V9.0 | |
| afterReady | V9.0 | |
| afterSeek | V9.0 | |
| afterStop | V9.0 | |
| onClose | V9.0 | |
| onPlay | V9.0 | |
| onReady | V9.0 | |
| onSeek | V9.0 | |
| onStop | V9.0 | |
| Template properties | hidden | V9.1 |
| name | V9.1 | |
| Template method | spawn | V9.1 |
| span properties | alignment | V9.1 |
| fontFamily | V9.1 | |
| fontStretch | V9.1 | |
| fontWeight | V9.1 | |
| fontStyle | V9.1 | |
| strikethrough | V9.1 | |
| subscript | V9.1 | |
| superscript | V9.1 | |
| text | V9.1 | |
| textColor | V9.1 | |
| textSize | V9.1 | |
| underline | V9.1 | |
| soap properties | wireDump | V9.1 |
| Soap method | request | V9.1 |
| streamDigest | V9.1 | |
| streamEncode | V9.1 | |
| streamFromString | V9.1 | |
| stringFromStream | V9.1 | |
| hostContainer method | postMessage | V9.2 |
| Fullscreen properties | transitions | V9.2 |
| defaultTransition | V9.2 | |
| loop | V9.2 | |
| timeDelay | V9.2 | |
| useTimer | V9.2 | |
| isFullScreen | V9.2 |
Global methods
| Method Names | Minimum Supported SDK Version |
| AFNumber_Format | V4.0 |
| AFNumber_Keystroke | V4.0 |
| AFPercent_Format | V4.0 |
| AFPercent_Keystroke | V4.0 |
| AFDate_FormatEx | V4.0 |
| AFDate_KeystrokeEx | V4.0 |
| AFDate_Format | V4.0 |
| AFDate_Keystroke | V4.0 |
| AFTime_FormatEx | V4.0 |
| AFTime_KeystrokeEx | V4.0 |
| AFTime_Format | V4.0 |
| AFTime_Keystroke | V4.0 |
| AFSpecial_Format | V4.0 |
| AFSpecial_Keystroke | V4.0 |
| AFSpecial_KeystrokeEx | V4.0 |
| AFSimple | V4.0 |
| AFMakeNumber | V4.0 |
| AFSimple_Calculate | V4.0 |
| AFRange_Validate | V4.0 |
| AFMergeChange | V4.0 |
| AFParseDateEx | V4.0 |
| AFExtractNums | V4.0 |
References
PDF reference 1.7
http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=51502
PDF reference 2.0
https://www.iso.org/standard/63534.html
Foxit PDF SDK API reference
sdk_folder/doc/Foxit PDF SDK DotnetCore API Reference.html
Note: sdk_folder is the directory of unzipped package.
Support
Foxit Support
In order to provide you with a more personalized support for a resolution, please log in to your Foxit account and submit a ticket so that we can collect details about your issue. We will work to get your problem solved as quickly as we can once your ticket is routed to our support team.
You can also check out our Support Center, choose Foxit PDF SDK which also has a lot of helpful articles that may help with solving your issue.
Phone Support:
Phone: 1-866-MYFOXIT or 1-866-693-6948
Updated on August 6, 2025